Unified API Access
Connect to multimodal AI models through one OpenAI-compatible API, making it easier to deploy, swap, and scale text, image, video, speech, and embedding workloads.
Access, route, and manage multimodal AI models through a unified hosting layer built for production reliability. From text and image to video, speech, and embeddings, this service helps teams simplify integrations, control spend, and maintain uptime while scaling AI applications with fewer operational bottlenecks.
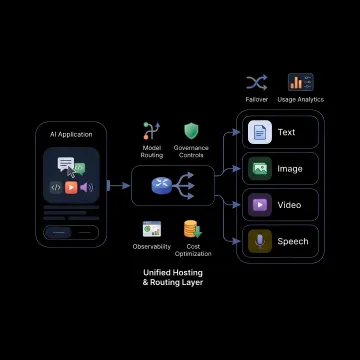
Unified hosting, routing, governance, and monitoring for multimodal AI workloads across leading model providers.
Connect to multimodal AI models through one OpenAI-compatible API, making it easier to deploy, swap, and scale text, image, video, speech, and embedding workloads.
Route requests to the best-fit model based on latency, cost, or output quality, reducing manual provider management while improving performance and efficiency.
Keep applications running with automatic failover, fallback lists, and multi-provider redundancy that protect against outages, rate limits, and model disruptions.
Set project limits, API key controls, roles, and access policies to manage usage responsibly while supporting enterprise oversight and safer AI operations.
Monitor latency, errors, usage, and model behavior with unified dashboards, logs, and alerts that support debugging, optimization, and production visibility.
Reduce unnecessary AI spend with smart routing, consolidated billing visibility, and usage analytics that help teams avoid premium-model overuse and billing surprises.
Multimodal AI model hosting services give teams a simpler way to run complex AI workloads without stitching together separate provider integrations. By centralizing access, routing, failover, governance, and monitoring, organizations can launch faster, compare models more effectively, and maintain better control over cost, uptime, and output quality across text, image, video, and speech use cases.
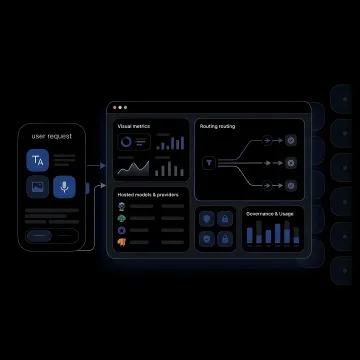
See how organizations improve reliability, control spend, and simplify multimodal AI operations.
"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."

"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."

"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."

"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."
"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."
"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."
"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."
"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."
"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."
Built to help teams operate AI systems with more control and less friction.
Host and switch across multiple model providers without rebuilding your application stack.
Automatic failover and redundancy help maintain uptime during provider outages or rate limits.
Unified logs, metrics, and alerts make production monitoring and troubleshooting far more manageable.
Governance features support safer access, budget protection, and consistent model usage across teams.
Built for teams deploying AI at scale.
This service is designed for organizations that need dependable multimodal AI infrastructure without the overhead of managing every provider separately. The focus is on simplifying how teams access, evaluate, route, and monitor models across text, image, video, speech, and embeddings. Rather than forcing a single-model strategy, the platform approach supports flexibility, resilience, and operational control as AI workloads grow. With unified access, governance controls, observability, and cost management built into the hosting layer, teams can move from experimentation to production with fewer integration burdens. The goal is straightforward: make enterprise AI operations easier to manage, easier to optimize, and more reliable over time.
A multimodal AI model can process or generate more than one type of data, such as text, images, audio, video, or embeddings. Examples include models that accept image and text prompts together, generate video from text, or combine speech and language tasks. In hosting environments, multimodal support matters because teams often need one platform that can manage several input and output formats consistently.
Talk with our team about multimodal AI infrastructure needs.

Simplifies integration across model providers.
Supports continuous AI application uptime.
Improves control over AI usage.
Share your use case, current stack, and goals. We’ll help you evaluate the right hosting, routing, and governance setup for your AI workloads.
To help us assist you faster, please include the reason for your message so the relevant team can reach out as soon as possible.
To help us assist you faster, please include the reason for your message so the relevant team can reach out as soon as possible.