Most teams don't overspend because they picked the "wrong" provider. They overspend because they compared APIs on sticker price alone — missing token structure, workload mismatch, and hidden operational costs that routinely 2–5x the actual bill.
This guide breaks down pricing across five major providers, exposes the hidden cost drivers that most comparisons ignore, and gives you a framework for choosing the right model for each workload.
Key Takeaways
- AI API pricing spans 600x across providers — from under $0.01 to over $30 per million input tokens
- Output tokens cost 2–8x more than input tokens depending on the provider and model
- Hidden costs (system prompts, reasoning tokens, cloud markups) routinely 2–5x the actual bill
- Batch API + prompt caching stacked together can cut effective per-call cost to roughly 25% of standard rates
- The cheapest per-token rate rarely produces the lowest cost per completed task
What Is AI API Pricing and How Does It Work?
LLM APIs charge on a per-token basis. The catch: they bill input and output separately — and the split matters more than most teams expect.
Input tokens cover everything sent to the model: your system prompt, conversation history, retrieved context documents, and the user's actual query. Output tokens are the model's response. According to OpenAI's tokenization documentation, 1 token equals roughly ¾ of an English word — so 1,000 tokens is approximately 750 words.
Output tokens cost more than input tokens — often by a wide margin — because generation requires more compute than processing. Across the providers covered here, that ratio ranges from 2x (DeepSeek, xAI Grok) to 8x (Gemini 2.5 Pro on short-context inputs).
Key Pricing Dimensions
Before comparing providers, understand these four levers:
- Per-token input/output rates — the base cost, billed per million tokens
- Context window size — larger windows cost more per call when filled; smaller windows limit long-document use cases
- Batch API discounts — 50% off at OpenAI and Anthropic for async workloads that don't need real-time responses
- Prompt caching discounts — up to 90% off repeated input prefixes at Anthropic; 75% at OpenAI for the GPT-4.1 family

Prices Have Dropped 90%+ Since 2023
Frontier-class API pricing has dropped sharply over two to three years. GPT-4 launched in 2023 at $30 input / $60 output per million tokens. Current GPT-4.1 pricing sits at $2 input / $8 output — a 93% reduction on input in roughly two years. Prices continue shifting with each new model generation, so always verify against official provider documentation before finalizing production budgets.
Top AI API Providers and Their Pricing
The five providers below were evaluated on market presence, model capability breadth, pricing transparency, and real-world production adoption. Each entry includes current pricing, a feature summary, and recommended use cases to help you match the right provider to your workload.
OpenAI
OpenAI offers the broadest model range of any single provider, spanning ultra-budget nano-class models up to premium o-series reasoning models. For most engineering teams, it's the default starting point for coding, general-purpose production chat, and agentic workflows — and it has the largest developer ecosystem of any AI provider today.
Key differentiators:
- 150x pricing range within a single provider family
- Batch API discount: 50% off for async workloads
- Prompt caching: up to 75% off on the GPT-4.1 family for matching prefixes
- o-series reasoning models for math, code, and complex multi-step tasks
| Model | Input / 1M | Output / 1M | Context Window |
|---|---|---|---|
| GPT-4.1 Nano | $0.10 | $0.40 | 1M tokens |
| GPT-4.1 | $2.00 | $8.00 | 1M tokens |
| o4-mini | $0.75 | $4.50 | Standard |
| o3 | $5.00 | $30.00 | Standard |
The GPT-4.1 family supports up to 1M token context windows — one of the largest in the OpenAI lineup. Best use cases: general-purpose production workloads, coding assistance, agentic multi-step tasks, high-volume classification.
Anthropic (Claude)
Claude comes in three tiers: Haiku (budget), Sonnet (mid), and Opus (flagship). It carries a strong reputation for instruction-following and consistent performance on coding and long-document analysis. Flagship Opus pricing has dropped 66% since Claude 3 launched (from $15/$75 to $5/$25 per million tokens), making frontier Claude far more accessible than it once was.
Key differentiators:
- Most aggressive prompt caching in the market: 90% off cached input tokens at read time (cache writes carry a 25% surcharge)
- 1M token context window on Sonnet 4.6 and Opus 4.8
- Reliable performance on multi-step reasoning and complex document analysis
| Model | Input / 1M | Output / 1M | Context Window |
|---|---|---|---|
| Claude Haiku 4.5 | $1.00 | $5.00 | 200K tokens |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 1M tokens |
| Claude Opus 4.8 | $5.00 | $25.00 | 1M tokens |
Best use cases: long-document analysis, code review, nuanced instruction-following, high-volume RAG applications where prompt caching eliminates most repeated input costs.
Google Gemini
Gemini offers strong value among Tier 1 providers, with a tiered Flash/Pro structure, multimodal capability (text, image, audio), and competitive pricing — especially on Flash tiers.
Key differentiators:
- Large context windows (1M tokens on current Pro and Flash models; Gemini 1.5 Pro supported 2M)
- Tiered input pricing on Pro that scales above 200K tokens
- Tight integration with Google Cloud Vertex AI for enterprise committed-use discounts
| Model | Input / 1M | Output / 1M | Context Window |
|---|---|---|---|
| Gemini 2.5 Pro (≤200K) | $1.25 | $10.00 | 1M tokens |
| Gemini 2.5 Pro (>200K) | $2.50 | $15.00 | 1M tokens |
| Gemini 3.5 Flash | $1.50 | $9.00 | 1M tokens |
| Gemini 3.1 Flash-Lite | $0.25 | $1.50 | 1M tokens |
Note that exceeding the 200K token threshold on Pro triggers a 2x input price increase — filling a large context window gets expensive quickly. Best use cases: long-context document analysis, multimodal workloads, cost-sensitive high-volume production, teams on Google Cloud infrastructure.
xAI (Grok)
xAI's Grok API has become a credible mid-tier challenger with meaningful price reductions across generations. xAI cut pricing from $5/$15 to $2/$10 per million tokens in 2024, and current Grok 4.3 pricing is competitive with Claude Sonnet and GPT-4.1.
Key differentiators:
- Cached input pricing at $0.20/1M — aggressive on repeated prefixes
- Grok Code Fast 1: dedicated coding-specialist model at $1.00/$2.00 per million tokens
- xAI Batch API offers 20–50% discounts on standard rates
| Model | Input / 1M | Cached Input / 1M | Output / 1M | Context Window |
|---|---|---|---|---|
| Grok 4.3 | $1.25 | $0.20 | $2.50 | 1M tokens |
| Grok Code Fast 1 | $1.00 | $0.20 | $2.00 | 256K tokens |
Grok Code Fast 1 makes xAI worth considering specifically for coding pipelines — the dedicated model at $1.00/$2.00 per million tokens undercuts most alternatives at similar capability. Best use cases: general chat and coding at competitive cost, high-volume tasks where batch discounts apply.
DeepSeek
DeepSeek is the clear budget leader, with per-token pricing well below every major US-based provider. A Reuters report on DeepSeek's 75% permanent price cut on its flagship V4-Pro model sent ripples through the market and pushed other providers to revisit their own pricing.
Key differentiators:
- Cache-hit input pricing approaches near-zero ($0.0028/1M on V4-Flash)
- Both a general chat model and a chain-of-thought reasoner at comparable pricing
- Context caching enabled by default; API responses include explicit cache-hit/miss token counts
| Model | Cache-Hit Input / 1M | Cache-Miss Input / 1M | Output / 1M | Context Window |
|---|---|---|---|---|
| DeepSeek V4-Flash | $0.0028 | $0.14 | $0.28 | 1M tokens |
| DeepSeek V4-Pro | $0.003625 | $0.435 | $0.87 | 1M tokens |
Tradeoffs include reliability considerations, data residency concerns for US enterprises, and the need for staged rollout testing before full production adoption. Best use cases: high-volume text generation, classification, summarization; chain-of-thought reasoning tasks where V4-Pro replaces significantly more expensive o-series or Opus-class models.
Hidden Costs That Affect Your Actual AI API Spend
Per-token sticker price is the starting point, not the finish line. Several factors routinely multiply the real bill.
The Token Overhead Problem
A typical production API call includes far more than the user's query. In a RAG application, the actual user message often represents 1–3% of the total input payload — everything else is overhead billed at the full input rate.
| Input Component | Typical Token Count |
|---|---|
| System prompt | 500–2,000 tokens |
| Retrieved context (RAG chunks) | 2,000–8,000 tokens |
| Conversation history | 500–3,000 tokens |
| User query | 20–100 tokens |
| Total input | ~3,000–13,000 tokens |

This means prompt engineering and RAG chunking strategy have a larger impact on cost than provider selection in many workloads.
Cloud Provider Markups
Routing through AWS Bedrock, Azure OpenAI, or Google Vertex AI adds a premium for unified billing, VPC peering, and compliance controls. Azure OpenAI listed GPT-4-Turbo at $11/$33 per million tokens while OpenAI's direct rate was $10/$30 — a ~10% markup.
At millions of tokens per month, that premium adds up fast. Always compare direct API rates against cloud marketplace rates before committing to a deployment path.
Reasoning Model Token Traps
Models like OpenAI's o-series or DeepSeek Reasoner generate internal "thinking" tokens before producing their final answer — and those thinking tokens are billed as output tokens. A single complex call can burn tens of thousands of output tokens in chain-of-thought processing. On o3 at $30/1M output, a call that produces 20,000 reasoning tokens costs $0.60 in thinking alone — before a single word of the actual answer.
The Visibility Gap
Many teams track only monthly AI spend totals rather than cost per transaction, per feature, or per workflow. Without granular attribution, there's no way to identify which workloads are driving overruns. Per-token and per-transaction tracking aren't optional hygiene — they're the minimum required to make cost optimization actionable.
How to Choose the Right AI API Provider
Match Model Tier to Task Complexity
Defaulting to a flagship model for simple tasks is the single most common source of API overspend. A straightforward framework:
| Workload Type | Recommended Tier | Example Models |
|---|---|---|
| Classification, extraction, summarization | Budget | GPT-4.1 Nano, Gemini Flash-Lite, DeepSeek V4-Flash |
| Production chatbots, content generation, coding | Mid-tier | Claude Sonnet, GPT-4.1, Gemini 2.5 Pro |
| Complex reasoning, agentic multi-step tasks | Flagship | Claude Opus, o3, DeepSeek V4-Pro |

Real-world cost comparison (10M input + 5M output tokens/month):
| Provider | Budget Model | Flagship Model | Monthly Difference |
|---|---|---|---|
| OpenAI | $3.00 (Nano) | $60.00 (GPT-4.1) | $57.00 |
| Anthropic | $35.00 (Haiku) | $175.00 (Opus) | $140.00 |
| $10.00 (Flash-Lite) | $62.50 (2.5 Pro) | $52.50 | |
| DeepSeek | $2.80 (V4-Flash) | $8.70 (V4-Pro) | $5.90 |
Cost Per Task, Not Cost Per Token
A cheaper model requiring more retries, longer outputs, or human review can cost more per business outcome than a pricier model. The right metric:
Normalized Cost = (token cost × total tokens including retries) ÷ successful completed tasks
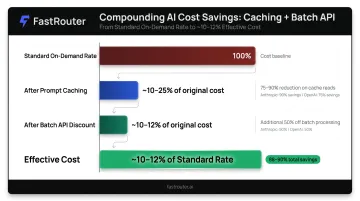
Stack Discounts for Maximum Savings
Two high-leverage strategies available across providers:
- Prompt caching — structure system prompts as static prefixes. Anthropic gives 90% off cache reads; OpenAI gives 75% off on GPT-4.1 family. Particularly impactful for RAG applications with large fixed context.
- Batch APIs — any workload tolerating async processing (nightly jobs, document pipelines, bulk classification) qualifies for 50% off at both OpenAI and Anthropic.
Stacking both strategies compounds the savings: applying a 50% batch discount on top of a 75–90% cache read discount brings effective per-call cost to roughly 10–12% of standard on-demand rates on supported workloads.
Multi-Provider Routing
For production teams running multiple workload types, routing simple requests to budget models and complex requests to flagship models reduces blended API cost significantly. Research from RouteLLM shows learned routers can reduce cost by more than 85% while maintaining 95% GPT-4-level performance on evaluated benchmarks.
Implementing that kind of routing in production, however, means managing multiple provider APIs, rate limits, and billing streams simultaneously. FastRouter's LLMOps platform addresses this by providing an OpenAI-compatible control plane across 100+ models with built-in cost governance and observability. Teams can unify everything under one endpoint. Switching between providers requires only a model ID change, not a code rewrite.
Right-Size Your Context Window
Large context windows (Gemini's 1M+, Claude's 1M) unlock long-document use cases, but every token in that window is billed at the input rate. Filling a large context window on Gemini 2.5 Pro at the >200K tier costs $2.50/1M input, which accumulates fast on high-volume workloads.
Use RAG to retrieve only relevant document chunks rather than sending entire documents, and set explicit max token limits on outputs to prevent verbose models from inflating output costs.
Conclusion
AI API pricing in 2025–2026 spans more than 600x across providers, but the cheapest per-token rate rarely translates to the lowest total cost of ownership. The right provider is determined by workload type, volume, context needs, and true cost per completed task — including retries and token overhead.
That gap makes a structured evaluation process essential. Define a unit of work, benchmark two to three providers on real production prompts, measure cost per accepted output (not cost per token), and revisit quarterly. Model generations and pricing both evolve faster than most engineering roadmaps.
For teams running multi-provider AI stacks, FastRouter brings routing, cost governance, and real-time observability under a single OpenAI-compatible API — so the right model gets used for the right task without manual intervention. Start your free audit at fastrouter.ai. No credit card required; set up in five minutes.
Frequently Asked Questions
What is the cheapest LLM API available right now?
DeepSeek V4-Flash holds the lowest published rate at $0.0028/1M tokens on cache hits, with cache-miss input at $0.14/1M. OpenAI's GPT-4.1 Nano comes in at $0.10/1M input non-cached. Cheapest per token doesn't mean cheapest per task, though — retry rates and output quality factor heavily into real-world cost.
How does token-based AI API pricing work?
Providers bill input tokens (prompt, context, instructions) and output tokens (model response) separately. Output tokens cost 2–8x more than input depending on the model, because generation requires more compute than processing. For reference, 1,000 tokens equals roughly 750 words of English text.
How does Claude API pricing compare to OpenAI?
Claude Sonnet 4.6 ($3.00/$15.00 per million) and GPT-4.1 ($2.00/$8.00 per million) sit in a similar mid-tier production range. Claude's 90% prompt caching discount on cache reads often makes it the lower-cost option in practice for applications with large, repeated system prompts, particularly in high-volume workloads where those cache hits stack up.
What are batch API discounts and when should I use them?
OpenAI and Anthropic both offer 50% discounts for asynchronous batch processing. Stacking batch processing with prompt caching can reduce effective per-call cost to roughly 25% of standard on-demand rates. This is ideal for document pipelines, nightly processing, and bulk classification jobs that don't require real-time responses.
What hidden costs should I watch for beyond per-token pricing?
Three main drivers to watch:
- System prompt and context overhead, which often represents 80%+ of total input in RAG applications
- Reasoning model "thinking" tokens billed at output rates, adding tens of thousands of tokens per complex call
- Cloud provider markups when routing through AWS Bedrock, Azure OpenAI, or Google Vertex AI
How often do AI API prices change?
Prices shift frequently — sometimes monthly — due to competitive pressure, new model launches, and provider discounting strategies. DeepSeek's 75% permanent price cut on V4-Pro is a recent example. Always verify against official provider documentation before production planning and schedule a quarterly pricing review.