Standard cloud billing tools weren't built for token-based pricing. They show you the total — not which team, feature, or request drove it. By then, the damage is done.
This guide covers the three capabilities that together form a complete LLM cost tracking solution:
- Observability — seeing where every dollar goes, in real time
- Governance — enforcing limits before budgets break
- Optimization — reducing spend without degrading output quality
Each pillar addresses a distinct failure mode — and together, observability, governance, and optimization form the LLMOps cost layer: the part of the LLMOps lifecycle where teams keep AI spend under control without sacrificing model quality. Together, they turn AI spend from an uncontrolled line item into a managed, measurable resource.
For teams operationalizing this, FastRouter is the LLMOps platform — one OpenAI-compatible API across 150+ models, sub-10ms overhead, zero markup, with built-in observability and cost governance.
Key Takeaways
- Traditional APM tools can't attribute costs at the token level — a dedicated LLM observability layer is required to get that granularity
- Multi-provider fragmentation (OpenAI, Anthropic, Vertex, Bedrock) makes unified spend visibility impossible without a gateway
- Real budget enforcement blocks or reroutes requests before a limit is hit, not after the damage is logged
- Prompt caching is the highest-impact cost reduction tactic available, with savings up to 90% on eligible input tokens
- Five metrics drive meaningful cost control: tokens per request, cost per team or feature, cache hit ratio, model mix, and anomaly rate
Why Traditional Monitoring Falls Short for LLM Costs
Standard APM and cloud billing tools were designed for fixed-resource pricing — compute hours, storage GBs, seats. LLM costs don't work that way. Every request carries a variable token count, a provider-specific rate, and separate pricing for input versus output. A lump-sum monthly invoice tells you nothing about which model, team, or workflow drove the spend.
The Multi-Provider Fragmentation Problem
A16z found 37% of enterprises now use five or more LLM providers, up from 29% the prior year. Each provider has incompatible cost structures:
| Provider/Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| Claude Sonnet 4.6 | $3.00 | $15.00 |
| Claude Haiku 4.5 | $1.00 | $5.00 |
| Gemini 3.1 Pro (≤200K) | $1.25 | $10.00 |
| Gemini 3.5 Flash | $0.30 | $2.50 |
| GPT-5.5 mini | $0.15 | $0.60 |
| AWS Bedrock Claude Opus 4.8 | $15.00 | $75.00 |
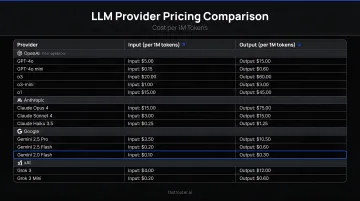
No single provider dashboard surfaces unified spend across all of these. Without a dedicated layer, teams reconcile separate invoices manually — or don't reconcile them at all.
Attribution and Enforcement Gaps
Fragmentation creates two more failure modes that general-purpose tools can't address:
- Tracks spend per user, team, feature, and environment — not just per API call — requiring structured metadata tagging that standard tools don't enforce
- Blocks requests before they exceed a budget, not just observes costs after the fact — passive monitoring alone isn't enough
Both problems get harder with dynamic pipelines. RAG chains, multi-step agents, and tool-calling loops expand token usage across steps in ways that are unpredictable without instrumentation at the inference layer itself. Gartner predicted at least 30% of GenAI projects would be abandoned by end-2025, citing escalating costs as a top cause — a problem that better attribution and enforcement could directly prevent.
Pillar 1: Unified Observability — Capturing Full Cost Visibility
Routing all LLM traffic through a single gateway or proxy layer is the most reliable instrumentation point. It captures every request regardless of provider or model, eliminating the blind spots that emerge when teams add per-service tracking independently.
Platforms like FastRouter operate as exactly this kind of unified AI gateway, consolidating traffic across OpenAI, Anthropic, Google Gemini, Vertex AI, and other providers through a single OpenAI-compatible endpoint. The result is a single source of truth for cost, latency, and usage data.
Metadata Tagging for Cost Attribution
Every LLM request needs structured metadata attached at call time:
- User ID — who made the request
- Team or department — which group owns the cost
- Environment — production, staging, or development
- Feature label — which product feature or workflow triggered it
FastRouter supports this through Dynamic Tags Per Request, allowing teams to attach custom metadata to individual API calls. This enables two reporting modes:
- Showback — informational cost reporting by team or user, for accountability
- Chargeback — internal billing against actual consumption
Neither works without consistent metadata tagging on every request — and enforcing that at the gateway layer means individual services don't implement it separately.
Real-Time Dashboards and Alerting
A complete observability dashboard should surface:
- Token consumption broken down by model and provider
- Cost per request over time
- Spend by team, feature, or environment
- Latency alongside cost — so the trade-off between speed and spend is visible, not hidden
FastRouter's unified dashboards cover cost, latency, and error rates across all connected models and providers, with per-team spend reporting and cost attribution built into its consolidated billing layer.
Anomaly detection is just as critical as reporting. When a specific user, feature, or model suddenly consumes tokens at an abnormal rate, teams should receive an automated alert rather than discovering the spike during a monthly invoice review. FastRouter's alerts system fires the moment AI spend, latency, or error rates breach defined thresholds.
One important distinction: estimated costs (token counts × published pricing) and actual costs (reconciled against provider invoices) are not the same number. Provider pricing changes, cache discounts apply inconsistently, and billable token counts sometimes differ from usage counts. FastRouter's consolidated billing and cost reconciliation layer is designed to bridge this gap across providers.
Pillar 2: Governance — Enforcing Limits Before Budgets Break
Observability tells you what happened. Governance determines what's allowed to happen.
Effective governance enforces spend limits at multiple levels simultaneously:
- API key or virtual key — per-integration spending caps
- User — individual consumption limits
- Team or department — group-level budget boundaries
- Provider — spend caps per provider relationship

FastRouter supports real-time limits by project, user, or key, with member roles and access controls to enforce organizational boundaries. The layered approach ensures that a single runaway workload — an agent loop, a verbose prompt pattern, a misconfigured pipeline — can't exhaust the organization's entire AI budget.
Rate Limits and Budget Caps
The distinction between monitoring and enforcement is direct: when a consumer hits a configured limit, requests should be blocked or rerouted, not just flagged in a log. A warning that arrives after a $10,000 overage isn't governance. It's a post-mortem.
Active enforcement means:
- Daily and monthly quota limits per key, user, or team
- Auto-blocking or fallback routing when limits are reached
- Alerts at 50%, 80%, and 100% of budget thresholds — not just at the ceiling
Access Control for High-Cost Models
Model-level access policies are one of the most direct cost levers available. The pricing spread between frontier and mid-tier models is substantial:
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| Claude Opus 4 | $15 | $75 |
| Claude Haiku 4.5 | $1 | $5 |
Routing general-purpose requests to frontier models by default is an expensive habit.
FastRouter's governance layer allows organizations to restrict which teams or API keys can call high-cost frontier models like GPT-5.5 or Claude Opus, while permitting broader access to cost-efficient alternatives. Most workflows don't need the most capable model. Access policies make that the default, not a guideline developers can ignore.
FastRouter's guardrail service adds another layer of cost protection by validating inputs and outputs at the gateway level: catching policy violations, unsafe content, and malformed responses before they generate unnecessary token spend or reach end users.
Pillar 3: Continuous Optimization — Reducing Spend Without Sacrificing Performance
Smart Routing and Model Selection
FastRouter's internal research shows most teams waste 40%+ of their AI budget by defaulting to frontier models for every request. The fix is cost-aware routing: sending simple queries to smaller models and reserving frontier capacity for genuinely complex tasks.
FastRouter's Auto Router handles this through the fastrouter/auto meta-model, which routes each prompt to the best-fit model from dozens of options based on quality, cost, and task requirements. AWS Bedrock offers similar intelligent prompt routing across model families. Either way, request complexity — not default habit — should drive model selection.
In mixed-complexity workloads, this routing approach typically reduces per-request costs without degrading quality for the majority of requests.
Caching and Batching
Prompt caching is the highest-leverage optimization with the strongest official evidence:
| Provider | Cache savings | Minimum tokens | Notes |
|---|---|---|---|
| OpenAI | Up to 90% off input tokens | 1,024+ | GPT-5.5 and newer models |
| Anthropic | Cache reads at 0.1× base input price | Varies | 5-min writes cost 1.25× base |
| Google Vertex AI | ~10% of standard input cost | 2,048+ | Gemini 2.5+ models |

The practical implication: place stable content — system prompts, tool schemas, policy text, retrieved context — at the beginning of your prompt where it can be cached. Reordering a prompt to enable caching often requires no logic changes.
Semantic caching goes further by serving cached responses for semantically similar queries, not just identical ones. The savings potential is higher, but it requires careful implementation to avoid returning stale or contextually mismatched outputs.
Self-Hosting and Fine-Tuning
Self-hosting open-source models (Llama, Mistral) makes economic sense only under specific conditions. Consider it when:
- Workload volume is high and predictable, so per-token API costs consistently exceed cluster infrastructure costs
- The break-even math holds up — this is workload-specific and shifts as provider pricing changes
- Fine-tuning is on the table for domain-specific, repetitive tasks with consistently long prompts
A fine-tuned smaller model can often match a larger general-purpose model's output quality on narrow tasks while consuming far fewer tokens per request.
Key Metrics Every LLM Cost Tracking Solution Should Monitor
The Five Core Metrics
| Metric | What to Track | Why It Matters |
|---|---|---|
| Tokens per request | Input and output separately | Detects prompt bloat and runaway completions |
| Cost per user/team/feature | Spend grouped by metadata dimension | Enables accountability and chargeback |
| Cache hit ratio | Cached tokens ÷ eligible repeated prefix tokens | Measures how much spend caching is avoiding |
| Model mix | % of requests by model tier | Identifies over-provisioning to frontier models |
| Cost anomaly rate | Frequency of spikes exceeding defined threshold | Measures how often governance gaps surface |
Tying Cost to Business Value
Total spend in isolation is a poor signal. What matters is cost per outcome — cost per resolved support ticket, cost per generated document, cost per accepted recommendation.
Intercom, for example, prices its AI agent at $0.99 per resolved outcome. That framing matters: it connects LLM spend to business value delivered, not just tokens consumed. Teams tracking cost-per-outcome can identify which features or workflows have the worst cost-to-value ratio and prioritize optimization accordingly.
That cost-per-outcome view only holds up if version changes are tracked alongside it. A new prompt template or model upgrade that improves quality but doubles token consumption may not trigger a spending alert — it just gradually inflates costs. Comparing spend across prompt versions and model changes catches this before it compounds. FastRouter's Model Council and Playground supports pre-switch cost analysis across models, and the Audit Service produces savings reports covering cost, quality, reliability, and latency comparisons.

Best Practices for Implementing LLM Cost Tracking at Scale
Implementation Checklist
- Centralize inference traffic through an observability-enabled AI gateway from day one — don't add per-service tracking as an afterthought
- Enforce metadata tagging as a non-negotiable standard across all services and environments
- Set budget alerts at 50%, 80%, and 100% of monthly limits — not just at the cap
- Run monthly cost-per-feature reviews to identify and retire or optimize wasteful workflows
- Document an escalation path for cost anomalies, including who receives the alert and what they're expected to do within what timeframe
Assign Ownership — This Is the Most Common Failure Mode
Deploying cost tracking tools without assigning ownership means those tools go unused. Someone must review the dashboards and act on what they show.
Two ownership steps matter most:
- Assign a named owner — a FinOps lead or platform engineering lead — responsible for LLM spend decisions
- Establish a weekly review cadence for cost dashboards, not just reactive monitoring when alerts fire
The goal isn't to restrict AI usage. It's to make high-volume usage observable and governable before it becomes an uncontrolled budget line. FastRouter's LLMOps platform accelerates this — with an audit service that surfaces overpayment patterns, model switch opportunities, and latency tradeoffs, alongside unified routing, real-time observability, guardrails, and cost governance from a single OpenAI-compatible control plane.
Frequently Asked Questions
What is LLM cost tracking?
LLM cost tracking is the practice of monitoring, attributing, and managing token-based expenses generated by large language model API calls across providers, teams, and workflows. Unlike billing summaries, it delivers per-request visibility and active budget enforcement before costs spiral.
How are LLM costs calculated?
Most providers charge per token — roughly 4 characters of text — with separate rates for input tokens (the prompt) and output tokens (the completion). Costs vary by model, and several input types carry distinct rates: reasoning tokens, cached tokens, and multimodal inputs such as images or audio.
Are LLM costs going down?
Per-token pricing has trended downward — Stanford's AI Index found inference costs dropped more than 280-fold between November 2022 and October 2024. But total organizational spend keeps rising because usage volume grows faster than unit prices fall, so governance matters more now than when unit costs were higher.
What is the difference between LLM cost monitoring and budget enforcement?
Monitoring observes and reports on costs after requests have been made. Enforcement actively blocks or reroutes requests before a budget ceiling is breached. A complete solution requires both layers working together.
How do I attribute LLM costs to specific users or teams?
Attach structured metadata — user ID, team name, feature label — to every LLM request at the gateway or SDK layer. Dashboards and analytics can then group and filter spend by any dimension, with no changes needed to individual services.
What metrics matter most for LLM cost optimization?
The highest-signal metrics are tokens per request (to detect prompt bloat), cost per business outcome (to measure ROI), cache hit ratio (to gauge caching effectiveness), and the share of traffic routed to high-cost frontier models (to identify over-provisioning).


