Cost Optimization
Reduce AI API spend through intelligent routing, batching, and model selection so workloads use the most efficient model for each task instead of defaulting to premium options.
Reduce runaway AI spend with smarter model routing, usage controls, and unified visibility across providers. This page covers practical ways to lower LLM costs without sacrificing reliability, output quality, or team velocity, helping organizations replace fragmented tooling with a more efficient, governed approach to AI operations.
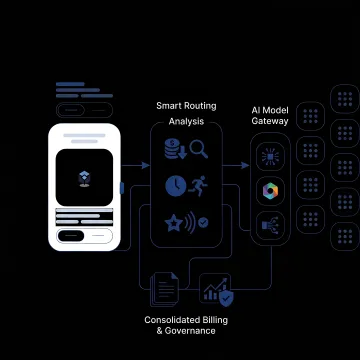
Targeted services that cut AI spend, improve visibility, and keep model usage efficient across providers.
Reduce AI API spend through intelligent routing, batching, and model selection so workloads use the most efficient model for each task instead of defaulting to premium options.
Analyze live API traffic to uncover savings opportunities, compare model quality and latency, and identify where expensive usage patterns can be replaced with lower-cost alternatives.
Set project and API key limits, apply access controls, and prevent budget overruns with governance tools designed to stop spend shocks before they impact operations.
Automatically route requests based on cost, latency, and output quality, helping teams balance performance and budget without constant manual tuning or provider switching.
Track spend, token consumption, and provider usage in one dashboard so finance, engineering, and operations teams can see where costs are rising.
Consolidate invoices across AI providers into one reconciled view, simplifying cost attribution, reporting, and budget management for multi-model environments.
LLM cost reduction services help teams cut unnecessary spend by matching each request to the right model, enforcing usage limits, and surfacing waste across providers. Instead of relying on one expensive default model, organizations gain routing, billing visibility, governance, and audit insights that support better cost decisions while preserving reliability, speed, and output quality.
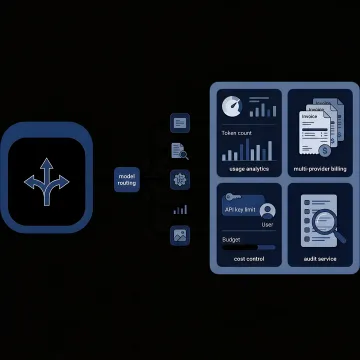
See how teams reduce AI costs while improving control and reliability.
"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."

"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."

"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."

"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."
"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."
"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."
"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."
"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."
"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."
Built to help teams control AI spend with less operational friction.
One OpenAI-compatible API simplifies multi-model adoption and reduces integration overhead across providers.
Built-in limits, roles, and access controls help prevent bill spikes and unmanaged usage.
Requests route by cost, latency, and quality to avoid unnecessary premium-model spend.
Automatic failover and redundancy keep AI applications running during provider outages.
Focused on efficient, governed AI operations.
FastRouter is built around a simple idea: businesses should be able to use the best AI models without losing control of cost, reliability, or governance. Rather than forcing teams to manage separate provider integrations, billing workflows, and routing logic on their own, the platform brings those capabilities together in one operational layer. Its approach centers on practical optimization—auditing live usage, comparing models, enforcing limits, and routing requests intelligently so organizations can reduce waste without slowing product teams down. With support for major model providers and enterprise-ready controls, FastRouter helps companies move from fragmented AI experimentation to a more disciplined, scalable, and cost-aware production environment.
LLM cost reduction services help organizations lower AI spending by improving how models are selected, routed, monitored, and governed. Instead of sending every request to the same expensive provider, these services use audits, routing policies, usage limits, analytics, and billing consolidation to reduce waste. The goal is to preserve output quality and uptime while making AI usage more efficient and predictable.
Talk with our team about practical LLM cost optimization options.

Built for governed multi-provider AI operations.
Simplifies adoption with familiar integration patterns.
Supports uptime with failover and redundancy.
Share your current AI stack, providers, and spend challenges to explore where optimization, routing, and governance can create measurable savings.
To help us assist you faster, please include the reason for your message so the relevant team can reach out as soon as possible.
To help us assist you faster, please include the reason for your message so the relevant team can reach out as soon as possible.