The frustrating part: AI spend rarely spirals because the technology is inherently expensive. It spirals because of bad routing defaults, invisible usage, overlapping tools, and the absence of any feedback loop connecting spending to outcomes.
This article breaks down exactly how AI costs accumulate, which drivers matter most, and what a structured reduction approach actually looks like — without cutting capability.
Key Takeaways
- Frontier models can cost 33x more per token than capable smaller models — model selection is the single biggest cost lever
- 75% of knowledge workers already use AI tools, and 78% bring their own — shadow usage creates spend you can't see or control
- Agentic workflows can consume over 1,000x more tokens than single-turn interactions, making per-task budgets non-negotiable
- Cutting AI costs means fixing how you route, monitor, and govern usage — not just renegotiating vendor contracts
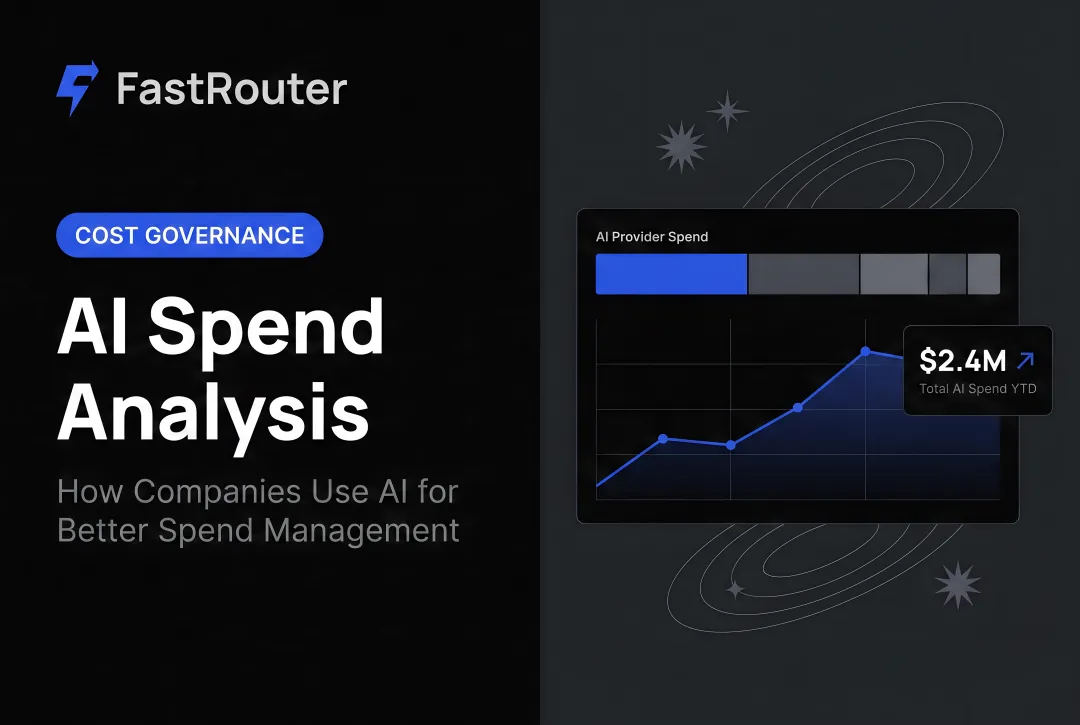
- FastRouter's free LLM audit identifies an average 46% cost reduction across real customer traffic
How AI Costs Typically Build Up
AI spend doesn't usually spike. It compounds.
The pattern looks like this: a developer defaults to GPT-4o because it's the most capable model available. Another team adds a new AI writing tool. A third spins up an agent pipeline and it grows from there. None of these feel like large purchases in isolation — but by the time finance consolidates vendor invoices at quarter-end, the total is well above what anyone budgeted.
Three mechanisms drive this escalation:
- Hidden early-stage costs — Individual teams expense AI tools directly. Developers default to frontier models for convenience. Usage grows without centralized tracking.
- Normalization of expensive defaults — Once a team uses a frontier model and it works, that choice becomes the default for every future task, regardless of whether it's warranted.
- Multiplicative scaling — What starts as a few API calls becomes dozens of concurrent pipelines across multiple business units, each generating token consumption without shared accountability.
The full picture only emerges when someone asks a pointed question: what are we actually spending on AI, and what is it producing? Most teams have the spend. Few have the visibility to explain it.
Key Cost Drivers for AI Spend
Understanding where costs originate is the prerequisite for reducing them. There are four primary drivers.
Model Over-Provisioning
Model selection is the most influential cost lever, and most teams are getting it wrong by default.
Official vendor pricing makes the scale of this problem concrete:
| Comparison | Frontier Model | Smaller Model | Input Cost Difference |
|---|---|---|---|
| OpenAI | GPT-4o ($5.00/1M tokens) | GPT-4o mini ($0.15/1M tokens) | 33x |
| Anthropic | Claude 3.5 Sonnet ($3.00/1M tokens) | Claude 3 Haiku ($0.25/1M tokens) | 12x |
| Gemini 1.5 Pro ($1.25/1M tokens) | Gemini 1.5 Flash ($0.075/1M tokens) | 17x |
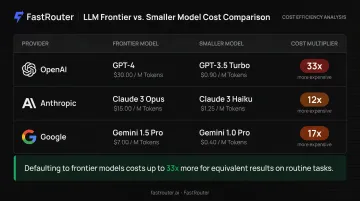
Defaulting to a frontier model for a classification task or a simple summary costs 12 to 33 times more than using a capable smaller model — with no meaningful difference in output quality for that task type.
Token Inefficiency
Even after choosing the right model, poor prompt design inflates costs. Oversized context windows, verbose instructions, and redundant API calls all increase token consumption without improving output.
This is an engineering and prompt design problem — one most teams can address without waiting on vendor pricing changes.
Tool Sprawl and Shadow AI
Microsoft and LinkedIn's 2024 Work Trend Index — surveying 31,000 workers across 31 countries — found 75% of knowledge workers use AI and 78% bring their own tools. Employees are already using AI faster than IT can track it.
The result: organizations pay for overlapping subscriptions across departments while additional usage flows through unapproved channels. Shadow AI creates a direct cost leak on top of the security exposure it already represents.
Absent Observability
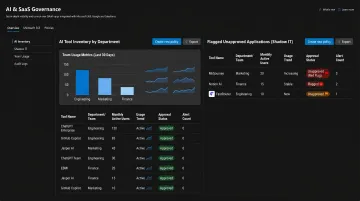
Without visibility into cost per model, per request, and per team, none of the other drivers surface until the invoice arrives. There's no feedback loop, no early warning, and no accountability. This is what allows over-provisioning, token waste, and shadow usage to persist.
Platforms like FastRouter address this directly by providing a unified LLMOps control plane with real-time cost governance and spend anomaly alerts across 100+ models from a single dashboard.
Agentic Workflows
Beyond these foundational gaps, autonomous agents introduce a compounding layer of cost risk that static pricing assumptions weren't built to handle. Research on token economics for LLM agents found agentic coding can consume over 1,000x more tokens than single-turn reasoning, with token use varying by up to 30x across identical tasks. Recursive planning, tool use, retries, and memory accumulation all drive this non-linear cost growth.
Static per-call pricing assumptions break entirely in agentic contexts.
Cost-Reduction Strategies for AI Spend
AI cost reduction happens at three levels: decisions made before deployment, how systems are governed during operation, and structural factors like prompt design, workflow architecture, and contracts. Each level has specific levers — and the highest-impact ones are often the least obvious.

Strategies That Change Decisions
The following strategies address choices made before or during AI system setup — where cost is easiest to prevent.
Right-size model selection to task complexity. Define a tiered model policy:
- Low-complexity tasks (classification, extraction, simple Q&A) → smaller, lower-cost models
- High-complexity tasks requiring deep reasoning or nuanced generation → frontier models, with documented justification
The cost differential is large enough that this alone can reduce token spend by an order of magnitude on routine workloads.
Rationalize the tool portfolio. Audit active AI subscriptions across all teams. Identify overlapping capabilities. Consolidate to an approved list, negotiate enterprise licenses where volume justifies it, and retire duplicates. This reduces both direct spend and the overhead of governing fragmented tooling.
Set per-team budget caps at deployment — not after the fact. Cost accountability needs to exist where decisions are made. Monthly spend limits at the team or project level create that accountability before usage grows, not when finance notices the overrun.
Require a measurable business case for every new AI deployment. Define the target outcome, the baseline being improved, and the review cadence before approving spend. This filters out low-value use cases before they become recurring line items.
Strategies That Change How AI Is Managed
Once systems are running, cost control depends on visibility and governance — not just initial configuration.
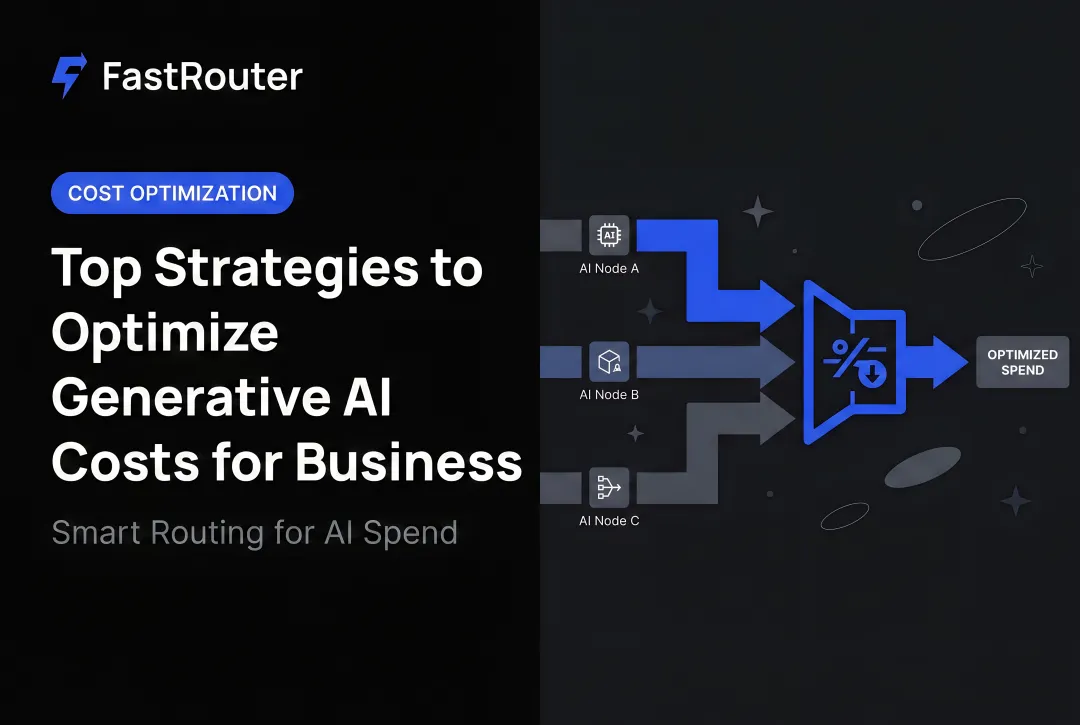
Implement intelligent model routing. Route each query to the cheapest model capable of meeting the quality threshold for that task type — not to a single default model for everything. Benchmark research on routing and cascading approaches shows potential API cost savings above 80% in controlled studies. Real production savings depend on your task mix and quality thresholds, but the direction is clear.
Putting this into practice across a multi-provider stack — without rewriting application code — is where platforms like FastRouter add leverage. Their free LLM audit tool identifies an average 46% cost reduction based on actual API traffic, not synthetic benchmarks.
Deploy real-time observability. Track cost per request, per model, per application, and per team. Without this, cost drivers remain invisible until invoices arrive. Consolidated dashboards that surface spend anomalies in real time — with alerts before problems compound — are essential at any meaningful scale.
Govern shadow AI regularly. Identify which tools are in active use outside approved channels, assess whether they duplicate sanctioned capabilities, and create intake paths that make it easier to use approved options than to work around them. According to Protiviti's survey of 345 executives, 65% of large organizations face shadow AI challenges and only 40% have a formal AI governance framework.
Tie AI spend to business outcomes through recurring reviews. Every significant deployment should have an owner, a measurable outcome metric, and a scheduled review. Spend on deployments that can't demonstrate value should be reduced or retired.
Strategies That Change the Context Around AI
Beyond model selection and governance, structural factors — prompt design, caching, agentic architecture, and contracts — drive significant cost variation that most teams leave unaddressed.
Optimize prompt engineering and context window management. Unnecessarily long prompts and overloaded context windows increase token consumption without improving outputs. Train teams on efficient prompt construction and incorporate prompt review into the deployment process.
Implement caching for high-repetition patterns. When similar prompts repeat across users or workflows, semantic caching can serve prior outputs without calling the model again. This is especially valuable in customer-facing applications where query patterns are predictable.
Redesign agentic workflows with explicit bounds. Autonomous agents without token consumption limits or loop detection can generate runaway costs quickly. Architect agentic systems with:
- Explicit LLM call budgets per task
- Circuit breakers that halt runaway processes
- Fallback behaviors for unexpected branches
- Alerts when consumption exceeds expected patterns
Align contracts to actual usage data. Many organizations over-commit on reserved capacity or model access tiers before usage patterns are stable. Review committed volumes against measured consumption at every renewal point, and separate experimental workloads from production commitments where vendors price them differently.
Every dollar saved through better contracting compounds — freeing budget for the higher-value deployments that actually move the needle.
Conclusion
Broad budget cuts eliminate value alongside waste — and rarely fix the underlying problem. Real cost control means tracing spend to its actual sources and addressing those specifically, not pulling back on AI across the board.
Effective cost governance combines decision-level controls (model policy, procurement, caps) with operational discipline (routing, observability, shadow AI governance) and structural improvements (prompt design, agentic architecture, contract alignment). None of these are one-time cleanup tasks. They're ongoing practices that compound in value as AI usage grows.
Organizations that get this right aren't spending less on AI. They're spending with more precision — and that difference shows up in both margins and output quality. Tools like FastRouter give engineering teams the routing intelligence, observability, and governance controls to put these practices into production without rebuilding infrastructure from scratch.
Frequently Asked Questions
How can I reduce AI spend?
Start with the two highest-leverage changes: right-size model selection so low-complexity tasks don't run on frontier models, and audit for duplicate subscriptions across teams. Together, these typically account for the largest share of waste.
What is the 30% rule for AI spending?
There's no formal AI-specific 30% rule. The closest published benchmark comes from BCG's 2025 cloud research, which found up to 30% of cloud spend is wasted through inefficient usage and weak cost controls. That FinOps-derived heuristic is sometimes applied informally to AI spend as a starting benchmark for addressable waste.
What is the 10-20-70 rule for AI spending?
BCG defines this as an AI transformation framework — not a spend allocation rule. It prescribes 10% of effort on algorithms, 20% on technology and data, and 70% on people and process change, reflecting that most AI value comes from adoption and workflow redesign rather than the models themselves.
What is the biggest driver of wasted AI spend?
Model over-provisioning and absent observability, and the two compound each other. When teams default to frontier models for every task and there's no visibility into what that's costing, there's no signal to prompt a change.
Does model routing reduce output quality?
Well-designed routing matches model capability to task requirements. For tasks that were previously over-served by expensive models, quality stays the same or improves — while cost falls. Quality only degrades when routing thresholds are set without testing against your real workload mix.
How do you track AI costs across multiple teams and providers?
You need a centralized observability layer that attributes usage by model, application, and team in real time — rather than relying on aggregated vendor invoices that arrive after the fact. LLMOps platforms like FastRouter are designed for exactly this, providing cross-provider cost visibility through a single dashboard.