LLM Gateway
Connect applications to major AI providers through one API layer, simplifying deployment while adding routing, failover, and centralized control for production workloads.
Deploy and manage production-ready AI applications with unified model access, real-time monitoring, failover protection, governance controls, and cost visibility. This page covers the core services that help teams launch faster, reduce provider risk, monitor performance continuously, and keep generative AI systems reliable, secure, and easier to scale.
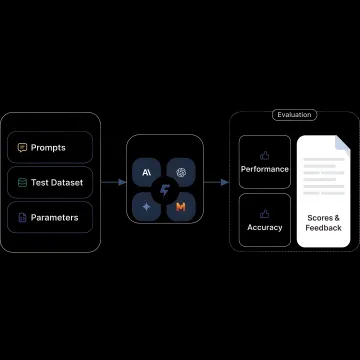
Unified services for deploying, monitoring, governing, and optimizing production generative AI applications across providers.
Connect applications to major AI providers through one API layer, simplifying deployment while adding routing, failover, and centralized control for production workloads.
Track latency, errors, usage, and model behavior with dashboards and logs that help teams troubleshoot issues and maintain visibility across live AI systems.
Receive real-time notifications for failures, cost spikes, and performance regressions so teams can respond quickly before users are affected.
Validate prompts and outputs with safety and compliance controls that reduce risky responses, malformed outputs, and policy violations in production.
Keep AI applications available with automatic fallback and multi-provider redundancy that reroutes traffic during outages, rate limits, or model instability.
Reduce unnecessary spend through smart routing, usage analytics, and budget controls that align model choice with quality, latency, and cost goals.
These services help teams move from prototype to dependable production AI with less operational friction. By combining unified model access, monitoring, alerts, governance, and automated failover, businesses can deploy faster while maintaining visibility into performance, spend, and reliability. The result is a more resilient generative AI stack that supports growth without multiplying vendor complexity or exposing teams to avoidable downtime and cost surprises.
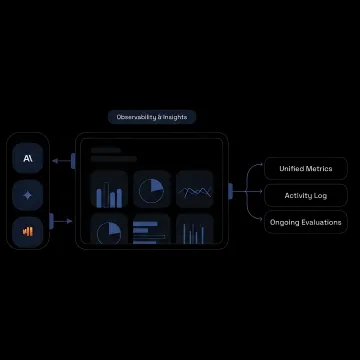
See how teams improve uptime, visibility, and cost control with unified AI operations.
"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."

"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."

"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."

"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."
"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."
"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."
"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."
"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."
"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."
Built for teams that need dependable AI infrastructure in production.
One OpenAI-compatible API connects applications to 150+ models without separate provider integrations.
Automatic failover and multi-provider redundancy help keep production AI workloads available 24/7.
Real-time dashboards, logs, and evaluations make monitoring performance and debugging issues far easier.
Routing, billing consolidation, and governance tools reduce waste and prevent unexpected AI cost spikes.
Focused on reliable, scalable AI infrastructure.
FastRouter is built around a simple goal: make production generative AI easier to deploy, monitor, and control. Instead of forcing teams to manage separate model providers, fragmented billing, and inconsistent reliability on their own, the platform brings routing, observability, governance, and failover into one operational layer. Its approach is designed for businesses moving beyond experimentation and into live applications where uptime, cost discipline, and response quality matter every day. With support for 150+ AI models through a single compatible API, FastRouter helps product, engineering, and platform teams simplify deployment decisions while gaining the visibility and safeguards needed to scale AI services with confidence.
These services help businesses launch and operate AI applications in production with the infrastructure needed for reliability and control. That typically includes unified model access, routing, failover, logging, observability, alerts, governance, and cost tracking. Instead of stitching together separate tools, teams get a more manageable way to deploy, monitor, and optimize AI workloads over time.
Talk with our team about deployment, monitoring, and reliability needs.

Simplifies integration across AI providers.
Supports continuous production availability.
Adds controls for secure AI usage.
Share your deployment goals, monitoring challenges, or reliability requirements, and we’ll help map the right solution for your AI applications.
To help us assist you faster, please include the reason for your message so the relevant team can reach out as soon as possible.
To help us assist you faster, please include the reason for your message so the relevant team can reach out as soon as possible.