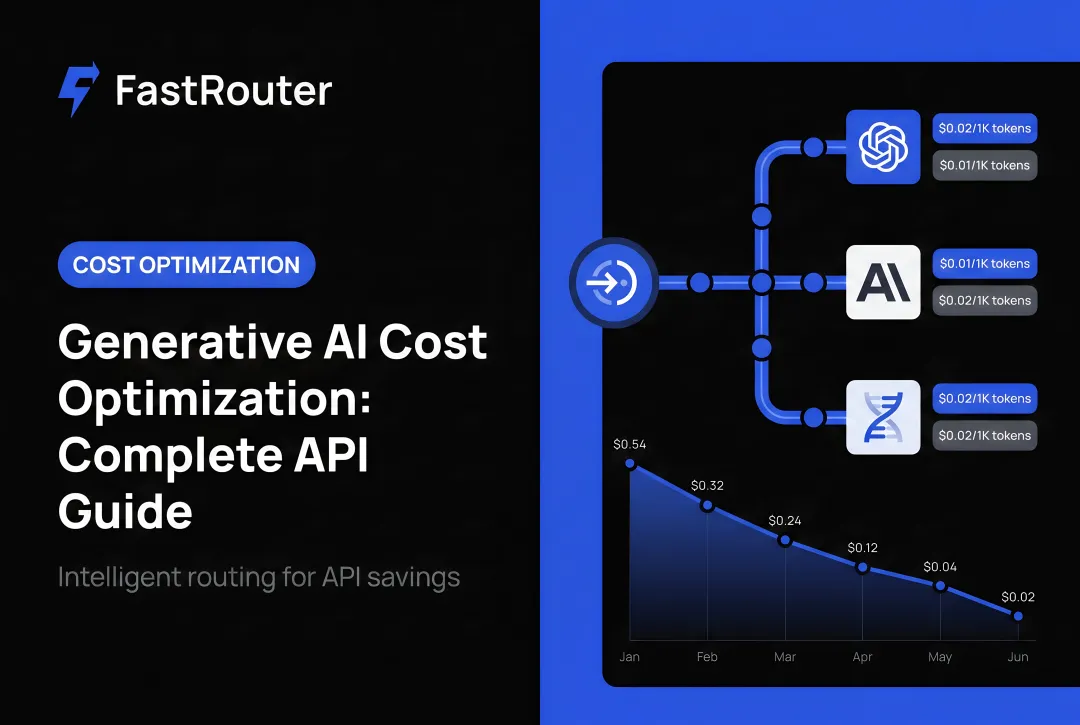
What makes GenAI costs particularly disorienting is how they behave. Unlike a SaaS subscription with a fixed monthly line item, API costs compound invisibly — through token accumulation across multi-turn conversations, agent tool calls, RAG context injection, and retry loops that silently re-consume tokens on every failed request.
The good news: this isn't an inherently uncontrollable problem. GenAI API costs become expensive because of specific decisions made early, management gaps during operation, and architectural choices in the surrounding system. This guide addresses all three.
For teams operationalizing this, FastRouter is the LLMOps platform — one OpenAI-compatible API across 150+ models, sub-10ms overhead, zero markup, with built-in observability and cost governance.
Key Takeaways
- GenAI API costs span token consumption, agent tool calls, RAG context, embeddings, and retry loops — not just model fees.
- Top cost drivers: wrong model tier, verbose prompts, uncontrolled team usage, and bloated context windows.
- Pre-deployment decisions matter most: model tier, prompt token budgets, and pricing structure set your cost baseline.
- In production, token-aware rate limiting, response caching, and per-team cost attribution prevent runaway spend.
- RAG pipeline optimization, cost-aware model routing, and async batch processing deliver the highest cost savings per engineering hour.
How GenAI API Costs Typically Build Up
Most teams treat GenAI API spend as a single line item — but a single user query can trigger multiple LLM calls, external API lookups, vector database retrievals, and token-heavy context injections, each billed separately.
The Compounding Effect
Cost accumulation is gradual by nature. A pilot that costs $200/month can scale non-linearly to $8,000/month as usage grows, agents chain more calls, and teams onboard without usage controls. The bills only become visible at month-end, by which point the damage is done.
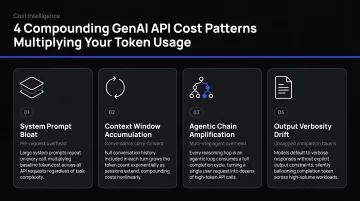
Four patterns explain most of that growth:
- Multi-turn agents send the entire prior conversation history on every call, so token usage grows quadratically as conversations lengthen.
- Tool call overhead adds token cost on every invocation — tool definitions and results are billed as input tokens, and this accumulates quickly inside agentic loops.
- RAG context injection turns retrieved chunks into billable input tokens. Larger chunks, more chunks per query, and absent caching all inflate costs before the model generates a single word.
- Retry loops consume tokens again on every resend without delivering user value — and most standard dashboards don't surface retries as a distinct cost category.
Each pattern compounds the others. An agent that retries tool calls inside a multi-turn conversation while injecting large RAG chunks can hit 10× the expected token count per session — well before any alert fires.
Key Cost Drivers for Generative AI APIs
Understanding where cost originates is what makes optimization targeted rather than arbitrary. Three drivers account for the vast majority of avoidable spend.
Model Selection Mismatch
This is the most impactful cost variable — and the most common mistake.
Consider the actual price differential: OpenAI's o1 model costs $15 input / $60 output per 1M tokens. GPT-5.5 mini costs $0.15 / $0.60. That's a 100x output cost difference. Using a frontier reasoning model for a straightforward classification or summarization task doesn't make the output better — it just makes it 100x more expensive.
FastRouter's audit service, which analyzes live API requests to surface cost-saving opportunities, has identified an average 46% cost reduction and $1,240 in monthly savings per audit across its user base — largely attributable to model-task mismatches.
Token Volume From Prompt and Context Decisions
Token volume is shaped by choices made around prompts and context:
- Long, verbose system prompts
- Excessive few-shot examples
- Large retrieved RAG chunks passed without filtering
- No output length constraints (allowing runaway completions)
Each of these inflates tokens per request and multiplies directly with scale. Output tokens are typically priced at 4–5x input tokens across major providers, so verbose completions compound cost particularly fast.
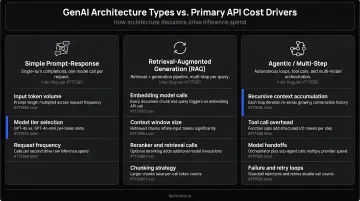
Architecture-Dependent Cost Drivers
The dominant cost driver shifts based on how the system is built:
| Architecture Type | Primary Cost Driver |
|---|---|
| Single-turn queries | Output token generation |
| Agentic systems | Number of LLM calls per user request (plan → tool call → re-evaluate → respond) |
| RAG applications | Volume of retrieved context injected into the prompt |
Identifying which driver dominates your specific system is the prerequisite for effective optimization. Applying token-reduction tactics to a system where the real problem is excessive LLM call count will produce minimal results — and leave the actual cost source untouched.
Cost-Reduction Strategies for Generative AI API Spend
Effective cost reduction depends on where the waste originates. The strategies below are grouped by where they intervene: decisions made before deployment, controls applied during operation, and architecture surrounding the LLM calls.
Pre-Deployment Decisions
Model Tier Alignment
Match each task type to an appropriately priced model rather than defaulting to the most capable option. A classification, extraction, or FAQ task doesn't need o1 or Claude Sonnet — it needs a model that handles the task at equivalent quality for a fraction of the price. Reserve frontier models for tasks that genuinely require complex multi-step reasoning.
Platforms like FastRouter support this through Virtual Model Lists and policy-based routing — allowing teams to define rules like "use GPT-5.5 mini for classification, route to GPT-5.5 for reasoning-heavy tasks" without embedding those decisions in application code.
Prompt Minimization at Design Time
Treat prompts as engineered artifacts with a token budget:
- Eliminate redundant instructions and repeated context
- Reduce few-shot examples to the minimum that maintains quality
- Set explicit output length constraints (
max_tokens, structured JSON responses) - Consolidate system prompt content to avoid repetition across calls
Pricing Model Selection
The right pricing structure depends on workload patterns:
- On-demand: Flexible, ideal for variable or unpredictable traffic
- Provisioned throughput: Better for high-volume, predictable workloads with consistent usage
- Batch inference: OpenAI, Anthropic, and Google Gemini each offer 50% cost discounts for asynchronous batch workloads — bulk document processing, content pipelines, and scheduled reporting are well-suited here
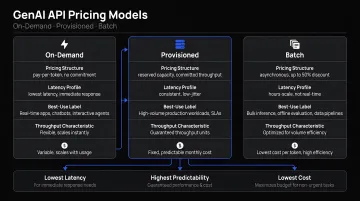
FastRouter exposes batch pricing tiers from OpenAI and Azure (including GPT-5.5, GPT-5.5 mini, and the o-series models), allowing teams to route async workloads to batch endpoints through the same unified API without separate provider integrations.
Use Case Scoping
Before building, verify the task actually requires generative AI. Classification tasks, structured data extraction, and rule-based routing are often better served by deterministic systems at a fraction of the cost. Restricting GenAI to tasks where output quality justifies the price prevents structural overspend from the start.
Once the right models and pricing structures are in place, the next layer of control is operational — governing how those models get used once they're live.
Operational Controls During Deployment
Token-Aware Rate Limiting and Quotas
Usage controls should be set at the token level, not just request count. The distinction matters:
- Rate limits control velocity (requests or tokens per minute)
- Quotas control cumulative volume (monthly or daily token budgets per team or project)
FastRouter provides real-time limits scoped per project, user, or API key — preventing traffic spikes from overwhelming budgets and stopping individual teams from quietly accumulating disproportionate spend.
Response Caching
Caching reduces both cost and latency. Three strategies apply depending on the use case:
- Exact prompt-response caching: Eliminates re-inference for identical queries — best for deterministic FAQs and templates
- Semantic caching: Extends caching to meaningfully similar queries using embedding similarity; research suggests semantic caching can reduce API calls by up to 68.8% across query categories
- Partial/context caching: Stores expensive, repeated prompt components (system instructions, RAG context). OpenAI's prompt caching can reduce costs by up to 75% for long prompts with repeated prefixes; Anthropic cache reads cost just 0.1x the base input price

Granular Cost Monitoring and Team-Level Chargeback
Aggregated billing numbers don't drive behavior change. When teams see their own spend broken down by model, application, and feature — and are accountable through internal chargeback or showback — usage naturally becomes more deliberate.
FastRouter's consolidated dashboard provides unified spend reporting across OpenAI, Anthropic, Gemini, and other providers in a single view, with per-team cost attribution and real-time alerts when spend breaches defined thresholds. This eliminates the need to reconcile separate invoices across providers.
Governance Policies and API Key Centralization
Shadow AI usage — teams spinning up their own provider API keys outside any monitoring layer — is a significant cost and compliance risk. Centralizing LLM access through a single gateway like FastRouter means all requests flow through governed, observable infrastructure. Teams can't route around spend controls by going directly to a provider.
Supporting governance controls include:
- Custom model lists per project (enforcing which models are accessible)
- Member roles and access controls
- Approval requirements before teams onboard new models or providers
- Prompt engineering training to establish efficient defaults
With operational controls in place, the final layer targets the architecture around your LLM calls — how context is assembled, when inference runs, and how requests are routed.
Architectural Optimizations Around LLM Calls
RAG Pipeline Optimization
In RAG-based applications, retrieved context is typically the largest driver of input token costs. Targeted optimizations:
- Reduce chunk size to retrieve only the most relevant segments
- Apply re-ranking to select top-k chunks before injection
- Use context compression — summarizing retrieved content with a smaller, cheaper model before passing it to the primary LLM
- Cache retrieval results to avoid redundant vector searches on similar queries
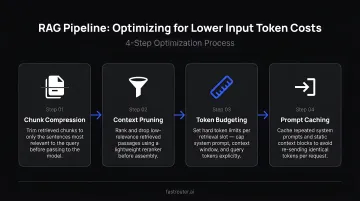
Research on prompt compression (LongLLMLingua) reports up to 94% cost reduction on long-context RAG benchmarks through compression alone, though quality validation against specific workloads is essential before deploying this in production.
Multi-Provider Model Routing
Build routing logic at the infrastructure layer that directs requests based on task complexity, token volume, latency requirements, or cost signals. Research on model routing (RouteLLM) shows cost reductions of more than 2x in some cases without performance loss.
FastRouter's routing layer decouples application code from specific model choices — teams can update routing policies, swap providers, or respond to pricing changes without re-deploying applications. The fastrouter/auto meta-model handles intelligent routing across 150+ models, with routing strategies available for cost optimization, low latency, and high throughput.
Conclusion
Reducing GenAI API costs isn't about spending less across the board — it's about identifying where cost is actually generated and addressing the source. Model mismatches, uncontrolled usage, architectural inefficiency, and context bloat each require different interventions. Applying blanket restrictions without understanding the root cause degrades capability without meaningfully moving costs.
API cost optimization is one layer of LLMOps — the operational discipline of running LLMs reliably in production. Effective cost optimization is also ongoing: usage patterns evolve, new models offer better cost-performance ratios, and teams surface new use cases that need their own controls. Organizations that build continuous monitoring, regular cost reviews, and cost-aware development practices into their workflow will sustain efficiency as they scale — not just during an initial setup sprint.
FastRouter's LLMOps platform supports that ongoing review cycle by analyzing live requests, surfacing cost-saving opportunities, and providing unified routing, observability, evaluations, and guardrails across 150+ models from a single control plane — giving teams a recurring mechanism to catch model mismatches, routing inefficiencies, and architectural drift before they compound into major overruns.
Frequently Asked Questions
How can generative AI reduce costs?
For API spend specifically, reduction comes from aligning model choice to task complexity, enforcing usage controls, and optimizing how context is constructed and cached — not from using AI less, but using it more precisely.
What are the best practices for optimizing content for generative AI?
Prompt optimization directly reduces token consumption: keep inputs concise, eliminate redundant instructions, set output length limits (via max_tokens or structured JSON), and cache repeated prompt components like system instructions. These changes reduce cost while often improving output consistency.
What is the most expensive part of a generative AI API call?
It depends on the architecture. For single-turn queries, output token generation is typically costlier than input. For agentic systems, the number of LLM calls per request (tool calls, planning loops) is usually the dominant factor. For RAG pipelines, the volume of retrieved context injected into the prompt drives input token costs.
Does caching work for generative AI API responses?
Yes — and it's highly effective. Exact caching handles identical queries; semantic caching extends this to similar ones; partial caching stores repeated system prompts or RAG context. TTL configuration should account for freshness requirements and the non-deterministic nature of some LLM outputs.
How do I choose between different LLM models to minimize cost?
Categorize tasks by complexity and quality requirements, then identify which can be served by smaller or open-weight models without sacrificing output quality. Benchmark cost-per-successful-output (not just cost-per-token) across candidate models before committing — the cheapest model per token isn't always the cheapest model per usable result.
What is token-based pricing in generative AI?
Most LLM APIs charge based on tokens processed in both input (prompt) and output (completion), where a token is roughly 3–4 characters of text. Longer prompts, verbose responses, and large retrieved contexts all directly increase the cost of every request — multiplied across every user and every call at production scale.