Introduction
Enterprise AI budgets are growing faster than most organizations can govern them. According to a16z, average enterprise spend across foundation model APIs, self-hosting, and fine-tuning reached $7M in 2023, with leaders expecting budgets to grow 2x to 5x in 2024.
More recently, 100 CIOs surveyed expected GenAI spending to grow another 75% over the next year. One-time innovation funds collapsed from 25% to just 7% of LLM spend — signaling that AI costs are now recurring, operational expenses, not pilot-phase experiments.
The problem isn't that GenAI APIs are inherently expensive. A budget-efficient model like GPT-5.5 mini runs at $0.15 per million input tokens. A frontier model like Claude Opus 4.8 runs at roughly $15.00 per million — a 100x difference. Costs become a problem when teams default to the largest model regardless of task, let prompts grow bloated, and have no visibility into what's actually driving spend.
This guide covers the full picture of GenAI API cost optimization — from integration decisions and prompt design to governance, routing, and the architectural choices that shape what you ultimately pay.
For teams operationalizing this, FastRouter is the LLMOps platform — one OpenAI-compatible API across 150+ models, sub-10ms overhead, zero markup, with built-in observability and cost governance.
Key Takeaways
- GenAI API costs compound through token accumulation, model defaults, and unmanaged call architecture
- Model selection, prompt design, and caching decisions drive more savings than negotiating API prices
- Cost reduction works across three levels: model/prompt choices, active governance, and architecture (caching, batching, RAG)
- Visibility and attribution must come before optimization — measure before you cut
- Cost management is continuous, not a one-time configuration
How GenAI API Costs Typically Build Up
Unlike infrastructure costs with fixed monthly line items, API costs accumulate one token at a time. Every request, every conversation turn, and every retry adds to the bill — with no natural ceiling unless you explicitly set one.
Gradual Accumulation vs. Episodic Spikes
Cost build-up takes two forms:
- Gradual: Daily token accumulation across user requests. A feature serving 10,000 users per day at 500 tokens per response generates 5 million output tokens daily before you've touched system prompts or context.
- Episodic: Sudden spikes from feature launches, traffic surges, or agentic loops without termination controls. Retry logic without exponential backoff can multiply costs in minutes.
The Input/Output Asymmetry
Output tokens cost more than input tokens — often significantly more. Current pricing from major providers shows:
| Provider & Model | Input (per 1M) | Output (per 1M) | Output/Input Ratio |
|---|---|---|---|
| OpenAI GPT-5.5 | $5.00 | $30.00 | 6x |
| Anthropic Claude Opus 4.7 | $5.00 | $25.00 | 5x |
| Google Gemini 3.1 Pro | $1.25 | $10.00 | 8x |
| Google Gemini 3.5 Flash | $0.30 | $2.50 | 8.33x |

Sources: OpenAI pricing, Anthropic pricing, Google Gemini pricing
Applications generating long completions or running multi-turn conversations face cost curves that diverge sharply from initial estimates.
In multi-turn interactions, previous response tokens are re-billed as input tokens on the next call. Each conversation compounds the cost of every prior exchange — a mechanic that catches most teams off guard when they first see their invoice.
Key Cost Drivers for GenAI APIs
Three factors drive the majority of GenAI API costs. Each one is addressable.
Model Tier Selection
This is the highest-leverage decision you'll make, yet most teams make it once and never revisit it. The spread between model tiers is substantial:
- GPT-5.5o mini: $0.15 input / $0.60 output per million tokens
- GPT-5.5 (2024-08-06): $2.50 input / $10.00 output — roughly 17x higher on a blended basis
- GPT-5.5 Pro: $21.00 input / $168.00 output — the top of the range
Through FastRouter's catalog of 150+ models, the same routing infrastructure gives access to everything from DeepSeek V4 Pro.1 at $0.27 input / $1.00 output up to Claude Opus 4.7 at $5.00 input / $25.00 output. The gap between the cheapest capable model and the most expensive frontier model can exceed 100x on specific tasks. Defaulting to the top tier without evaluating whether the task requires it is where most budget disappears.

Prompt Engineering Quality
Bloated system prompts, unstructured context stuffing, and redundant few-shot examples create silent token overhead that scales with every call. A 2,000-token system prompt at $0.60/M output tokens, sent 50,000 times daily, costs ~$27/day — versus ~$5.40/day for a 400-token equivalent. That's a $645/month difference from a single prompt. This overhead is invisible in most cost reports because it's baked into every call, not attributed to a specific feature or incident.
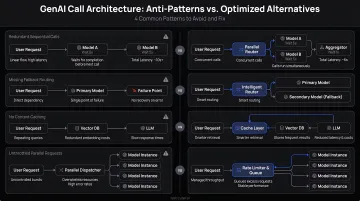
Call Architecture
How requests are structured determines whether the same user-facing value is delivered at 1x or 5x the necessary cost:
- Synchronous calls for non-time-sensitive tasks vs. batch processing
- Generating fresh completions for semantically identical queries vs. caching
- Retry logic without backoff limits vs. capped exponential backoff
- Full knowledge bases stuffed into context vs. retrieval-augmented generation
Each of these patterns compounds: a caching miss combined with an oversized model and no batch processing can turn a $500/month API bill into a $5,000 one.
Cost-Reduction Strategies for GenAI APIs
Cost reduction requires examining three categories: decisions made before integration, governance applied during operation, and the architectural context surrounding the model.
Strategies That Reduce Costs by Changing Decisions
Right-size model selection by task. Not every task needs a frontier model. Classification, extraction, simple summarization, and structured data parsing often perform comparably on smaller instruction-tuned models at a fraction of the cost. Implement tiered routing that sends simpler queries to lower-cost models automatically.
LMSYS RouteLLM demonstrated cost reductions of over 85% on MT-Bench and 45% on MMLU compared to using GPT-5.5 exclusively, while maintaining 95% of GPT-5.5 performance. FastRouter's fastrouter/auto meta-model applies this principle directly — routing each prompt to the best-fit model across its catalog, optimizing for cost, quality, and latency without requiring manual routing logic.
Use PEFT/LoRA fine-tuning for high-volume specialized tasks. Fine-tuning a smaller open model with LoRA or QLoRA trades a one-time tuning cost for persistent per-token savings. LoRA reduces trainable parameters by roughly 90% versus full fine-tuning. Anyscale found Llama 3.3.3 was 30x cheaper than GPT-5.5 for comparable summarization accuracy on a specific factuality benchmark.
Compress and standardize prompts. Establish a prompt governance practice:
- Review system prompts for token efficiency before deployment
- Use structured output formats (JSON schema) to constrain completion length
- Replace few-shot examples with fine-tuning or retrieval where practical
- Set baseline token counts per prompt and flag deviations in code review
Align pricing model to workload type. Pay-as-you-go works well for unpredictable or low-volume usage. Provisioned throughput can offer per-token savings for predictable, high-volume workloads — but becomes a sunk cost when utilization drops below its minimum threshold. Audit workload patterns before committing to reservations.
Strategies That Reduce Costs by Changing How APIs Are Managed
Instrument every API call with cost telemetry. Capture input tokens, output tokens, model ID, latency, and a feature tag on every request. Without attribution, you can't know whether your customer-facing chat feature or your internal summarization pipeline is driving 80% of spend. FastRouter provides unified dashboards, alerts for cost spikes, and consolidated multi-provider billing across OpenAI, Anthropic, Gemini, and others into a single cost view — eliminating the need to reconcile separate provider invoices manually.
Set explicit token budgets at the application layer. Use max_tokens parameters, stop sequences, and system-level instructions that constrain output verbosity. Without these guardrails, models tend toward verbose completions that inflate output token costs unnecessarily. Output tokens cost 5x–8x more than input tokens depending on the provider — unconstrained generation is expensive by design.
Implement semantic caching. Many production applications receive semantically equivalent questions repeatedly. A cache keyed on embedding similarity intercepts near-identical queries and serves cached responses without invoking the model.
A 2024 arXiv study on semantic caching reported API call reductions of up to 68.8% with cache hit rates between 61.6% and 68.8%, using a similarity threshold of 0.8 as the optimal balance between hit rate and accuracy. This works best for stable, factual query patterns — less so for context-dependent or multi-turn interactions.
Monitor per-feature cost ratios and set alert thresholds. Track KPIs like cost per 1,000 user interactions and token efficiency ratio. FastRouter's alerts and notifications service notifies teams the moment AI spend, latency, or error rates breach defined thresholds — catching anomalies before they compound across billing cycles. FastRouter's audit service has helped teams achieve an average 46% cost reduction by surfacing cost-saving opportunities within actual production usage patterns.
Strategies That Reduce Costs by Changing the Context Around APIs
Shift non-latency-sensitive workloads to batch processing. Both OpenAI and Anthropic offer batch endpoints at 50% of standard API pricing for asynchronous processing. Summarization, classification, embedding generation, document processing, and offline analytics have no real-time requirement — routing them through synchronous endpoints at full price is a default worth breaking. FastRouter's batch processing support routes high-volume workloads to batch endpoints across providers.
Replace long static prompts with RAG. Instead of embedding full knowledge bases into system prompts, use a vector store to retrieve only relevant context at query time. Pinecone reported 75% cost reduction versus sequential document processing while preserving 95% accuracy and using just 25% of the tokens. Stuffing a 1M-token context can cost $0.50–$20 per call depending on the model — across 10,000 daily requests, that's $5,000–$200,000 in context costs alone.

Use provider-native prompt caching for repeated prefixes. For applications that share long system prompts across many requests, Anthropic's prompt caching prices cache reads at 0.1x the base input price. OpenAI's prompt caching applies automatically to prompts of 1,024 tokens or longer and can reduce input token costs by up to 90% on eligible models (GPT-5.5 at 75%, GPT-5-nano and GPT-5.5 at 90%). The savings are real but require stable, repeated prompt prefixes — dynamic system prompts won't benefit.
Apply quantization for self-hosted or hybrid deployments. For teams serving open models, quantization cuts memory overhead significantly without changing the model itself. Key benchmarks:
- Moving from FP32 to INT8 reduces memory requirements by approximately 4x (NVIDIA benchmarks)
- Hugging Face's bitsandbytes LLM.int8() achieves roughly 2x memory reduction in practice
- Overall memory footprint drops 50–75% with minimal accuracy degradation
Conclusion
Cutting GenAI API costs starts with understanding where cost originates — whether in model tier defaults, prompt inefficiency, unmanaged call volume, or architectural choices like synchronous routing where batch processing would suffice. Switching to a cheaper model without fixing these root causes doesn't produce lasting savings. The same inefficiencies apply — just at a lower base rate.
Cost optimization isn't a one-time configuration checkpoint. Models evolve, pricing structures change, and usage patterns shift as products grow. Strategies that work today need revisiting when workloads scale, providers reprice, or application architecture changes.
Cost optimization is a core function within LLMOps — the operational discipline for running LLMs reliably in production. The teams that keep costs under control treat this as ongoing operational discipline — with the observability, spend governance, and routing logic in place to act on what the data shows. FastRouter's LLMOps platform brings these controls together in one place: unified routing, observability, cost governance, evaluations, and guardrails across 150+ models through a single OpenAI-compatible API.
Frequently Asked Questions
What are the pricing models for AI software?
AI software typically uses four models: per-token (pay-as-you-go), provisioned throughput (flat reservation for guaranteed capacity), subscription tiers, and consumption-based enterprise agreements. High-volume, predictable workloads benefit from provisioned throughput; variable usage suits pay-as-you-go.
What is usage-based pricing in AI?
Usage-based pricing charges based on actual consumption — tokens, API calls, GPU hours, or inference requests — rather than a fixed fee. Costs stay low at low volumes but compound quickly at scale without governance controls in place.
What are the best billing systems for AI companies with complex pricing models?
Purpose-built FinOps platforms with GenAI cost attribution (such as FastRouter's consolidated billing), cloud-native billing exports (AWS CUR, GCP BigQuery billing export, Azure Cost Management), and custom ledger approaches using ClickHouse or BigQuery for high-volume token-level metering are the main options worth evaluating.
How can I reduce my OpenAI or Anthropic API bill without sacrificing output quality?
Five high-impact levers:
- Use semantic caching to avoid redundant API calls
- Compress system prompts to reduce input token volume
- Set
max_tokenslimits on every request - Route simpler tasks to smaller, cheaper models via intelligent routing
- Shift eligible workloads to batch API endpoints — both OpenAI and Anthropic offer 50% lower per-token rates for batch processing
What is the difference between input and output token costs?
Output (completion) tokens cost more than input tokens because generation is computationally heavier than processing. Current output-to-input ratios range from 5x (Anthropic) to over 8x (Google Gemini), meaning long-response or multi-turn workloads carry disproportionately higher costs than short, structured ones.
How does model routing help reduce GenAI API costs?
Model routing uses semantic classification or rules-based logic to direct each request to the lowest-cost model capable of handling it — sending simple queries to small, inexpensive models and escalating to frontier models only when task complexity requires it. LMSYS RouteLLM demonstrated cost reductions exceeding 85% in benchmark testing while maintaining 95% of GPT-5.5 performance.