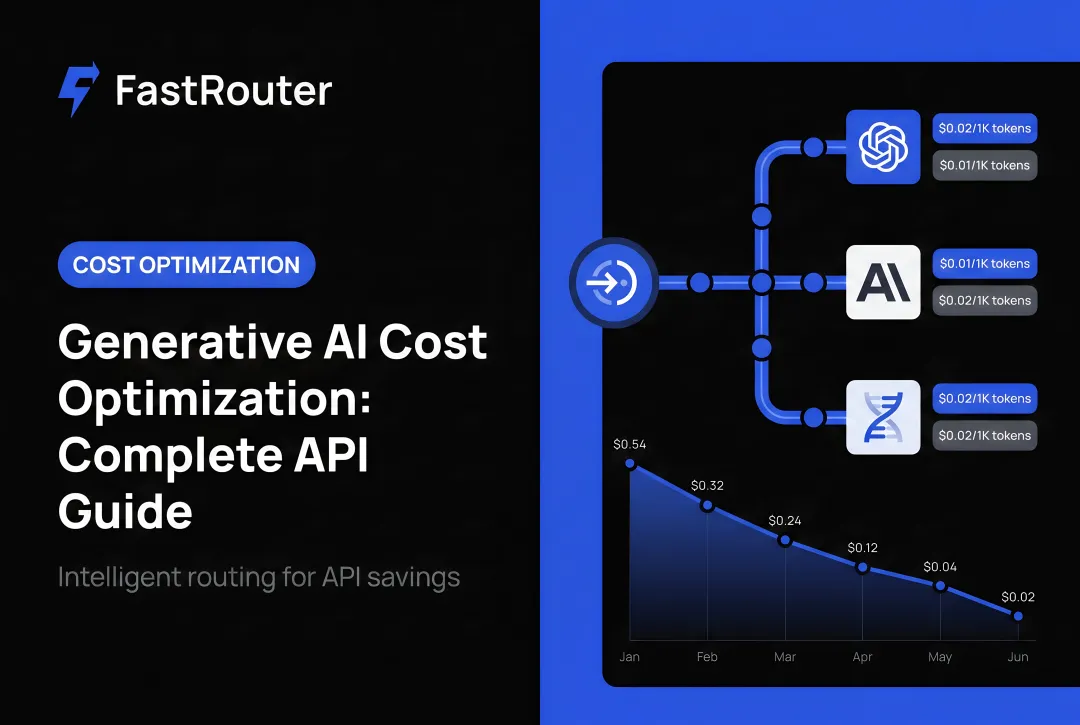
Introduction
Enterprise AI spending has a scale problem. According to a16z's 2024 enterprise survey, the average enterprise spent $7 million on generative AI in 2023 — across foundation model APIs, self-hosting, and fine-tuning — with nearly every respondent planning to increase that by 2–5x in 2024.
That trajectory has consequences. Gartner predicts at least 30% of GenAI projects will be abandoned after proof of concept by end of 2025, with escalating costs cited as a primary reason.
Most of that expense isn't inevitable. LLMs get expensive because of uninformed model choices, unmanaged token usage, and poor architectural decisions — problems that are fixable once you know where to look.
This guide covers how LLM costs actually build up, which drivers matter most, and three distinct categories of reduction strategies — organized by where the lever actually lives in your system.
For teams operationalizing this, FastRouter is the LLMOps platform — one OpenAI-compatible API across 150+ models, sub-10ms overhead, zero markup, with built-in observability and cost governance.
Key Takeaways
- LLM costs compound silently across token usage, model selection, infrastructure, and supporting services
- Output tokens cost 4–5x more than input tokens across major providers — output length is a first-order cost lever
- Model tier differences create 12x to 60x cost multipliers; most teams default to frontier models without evaluating whether cheaper ones would work
- Batch processing cuts costs by 50% at both OpenAI and Anthropic for non-real-time workloads
- Semantic caching, model routing, and RAG architecture can reduce ongoing LLM spend by 40–70% for most production workloads
How LLM Costs Typically Build Up
LLM costs don't arrive as a single line item. They accumulate across layers: token charges, vector database operations, embedding calls, guardrails, and third-party tooling — each of which looks negligible at low volume.
The trap is the prototype phase. A few hundred queries per day feels cheap. Scale that same architecture to thousands of requests per hour — with long system prompts and full conversation history appended to every call — and costs multiply fast. The architecture decisions that create expensive patterns are usually locked in before anyone notices.
By the time costs become visible (through a traffic spike, a monthly invoice review, or an audit), the underlying design choices are already embedded in production. Understanding these cost drivers before you scale is where you have the most control — after that, redesigning a live system is costly and slow.
Key Cost Drivers in Gen AI Applications
Token Volume and Output Pricing
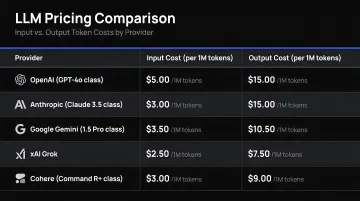
Every API call involves two components: input tokens (system prompt + conversation history + retrieved context + user message) and output tokens (the generated response). The asymmetry matters: output tokens are priced 4–5x higher than input tokens across major providers.
Current pricing examples:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Ratio |
|---|---|---|---|
| OpenAI GPT-5.5 mini | $0.15 | $0.60 | 4x |
| OpenAI GPT-5.5 | $2.00 | $8.00 | 4x |
| Anthropic Claude Sonnet 4.6 | $3.00 | $15.00 | 5x |
| Anthropic Claude Haiku 4.5 | $0.25 | $1.25 | 5x |
| Google Gemini 3.5 Flash (<128K) | $0.075 | $0.30 | 4x |
Unconstrained output generation is one of the most common sources of avoidable cost in production systems.
Model Selection as a Cost Multiplier
Most teams default to the most capable model available. That's a costly habit. The price gap between frontier models and task-appropriate smaller models is significant:
- Claude Opus 4.8 vs. Claude Haiku 4.5: 60x price difference
- GPT-5.5 vs. GPT-5.5 nano: 20x price difference
- Claude Sonnet 4.6 vs. Claude Haiku 4.5: 12x price difference
For tasks like classification, summarization, or structured extraction, a smaller model often delivers equivalent results. Preply reduced overall LLM spend by 46% by optimizing their top 15 prompts by token volume — switching to smaller models and restructuring output formats, with A/B tests to catch quality regressions.
Deployment Mode and Batch Processing
API pricing scales directly with usage — no floor, no ceiling. Self-hosted GPU infrastructure introduces fixed costs that only become economical at sustained high utilization. Neither is inherently better; the choice depends on your volume and ops maturity.
Within API-based deployments, batch processing offers a direct 50% cost reduction for non-real-time workloads. Both OpenAI's Batch API and Anthropic's Message Batches charge at 50% of standard pricing. For document processing, data enrichment, or content generation pipelines, there's no architectural reason to use real-time inference.
Supporting Infrastructure Costs
Vector databases, embedding models, and caching layers add real cost that grows with volume:
- Pinecone Standard: $50/month minimum, $16–18 per 1M read units
- Weaviate Flex: starts at $45/month, $0.01668 per 1M vector dimensions
As one a16z executive observed, "LLMs are probably a quarter of the cost of building use cases" — meaning development and infrastructure account for the majority. Teams that model only token costs in their projections routinely underestimate total system spend by a significant margin.
The Cost of Poor Visibility
Without workload-level attribution, teams can't identify which features, models, or usage patterns drive spend. This is itself a cost driver — you can't optimize what you can't see.
Effective visibility requires spend attribution at the workload level — by feature, team, and model — not just aggregate API invoices. Tools like FastRouter address this with per-team cost reporting, dynamic request tagging, and real-time spend alerts across providers. In practice, surfacing where teams are over-using frontier models has uncovered an average 46% cost reduction opportunity and $1,240 in monthly savings per audit.
Cost-Reduction Strategies for LLMs
Effective optimization requires addressing cost at three different layers: decisions made at design time, how the system is managed in production, and the surrounding architecture. Each layer requires different tactics.
Strategies That Reduce Costs by Changing Decisions
These are the highest-leverage interventions because they shape every subsequent inference request.
Right-size model selection from the start. Build a lightweight evaluation framework using your actual production prompts, not generic benchmarks. Start with the cheapest model tier, measure output quality against a ground-truth set, and escalate only when cheaper models measurably fail. The 12–60x cost multipliers between tiers make this the single most impactful decision you can make.
Use batch processing for non-urgent workloads. Any task that doesn't require an immediate response — document classification, report generation, data enrichment, content pipelines — qualifies for batch inference. Both OpenAI and Anthropic offer 50% discounts for batch API usage. Many teams leave this on the table by defaulting to real-time inference everywhere.
Design prompts with cost in mind at authorship time. System prompts are resent with every single API call. One extra paragraph of edge-case context, multiplied across millions of requests, adds real money. Keep system prompts concise, remove examples that only apply to rare cases, and explicitly instruct the model to constrain response length.
Use fine-tuning to eliminate long few-shot prompts. When a use case requires consistent output format or domain-specific reasoning, a fine-tuned smaller model can often match a larger model with a long prompt — at a fraction of the token cost per request. The upfront fine-tuning investment typically pays back quickly at production volume.
Strategies That Reduce Costs by Changing How LLMs Are Managed
Production cost management requires active, continuous control: configuration alone won't hold the line as usage scales.
Implement prompt caching for stable prefixes. Native prompt caching (available from OpenAI and Anthropic) reuses the KV cache for repeated system prompt prefixes. OpenAI reports up to 90% reduction in cached input costs; Anthropic charges cache reads at 10% of base input price. For any application with a long, stable system prompt, this is a low-effort win with immediate payback.
Layer in semantic caching for high-overlap query patterns. Semantic caching converts incoming prompts to vector embeddings and returns stored responses when a new query is sufficiently similar to a prior one. Redis reported one customer (Mangoes.ai) achieving a 70% cache hit rate and 70% reduction in LLM spend using semantic caching. Hit rates are workload-dependent, but support bots and internal knowledge tools are natural candidates.
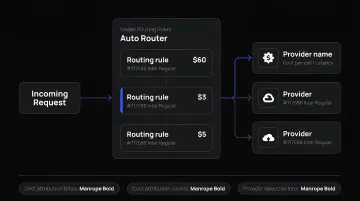
Apply model routing to match query complexity to model cost. Real-world query distributions are skewed — a large share of requests are simple enough for cheap models. A routing layer (even a lightweight classifier) can direct traffic accordingly. FastRouter's Auto Router implements this automatically, routing each prompt to the best-fit model across 100+ options based on cost, quality, and latency signals. Custom routing rules and Virtual Model Lists let teams define their own routing policies when needed.
Constrain output tokens actively. Use max_tokens parameters, output-length instructions, and format directives (bullet points, character limits, structured JSON) to prevent over-generation. Since output tokens are priced at a premium, this is a continuous discipline, not a one-time configuration.
Track cost per business KPI. Raw token spend is hard to act on. Cost-per-resolved-ticket, cost-per-processed-document, or cost-per-generated-report creates unit economics that reveal whether the system is efficient. FastRouter's per-team cost attribution and dynamic request tagging make this kind of tracking feasible without building custom instrumentation.
Strategies That Reduce Costs by Changing the Context Around LLMs
Once runtime controls are in place, the next layer to examine is architecture — specifically, how much context gets passed to the model on each call.
Replace large context windows with targeted RAG retrieval. Stuffing full documents into every prompt is one of the most common sources of token inflation. A well-designed RAG pipeline retrieves only the most relevant passages per query, keeping input tokens lean.
That said, RAG isn't always the right call: a 2024 arXiv study found that long-context models outperformed RAG by 7.6–13.1% on certain tasks. A Self-Route approach — directing queries to RAG or long-context based on complexity — reduced cost by 39–65% while maintaining comparable performance.
Optimize chunking strategy for cost and accuracy. Chunking decisions affect both context size and embedding generation costs. LlamaIndex benchmarks found accuracy peaked at chunk_size 1024; LangChain's table-RAG tests showed 50-token chunks produced only 30% accuracy by breaking structured content. As a general rule: use larger chunks (512–1024 tokens) for prose-heavy content, and smaller chunks for structured or tabular data where precision matters more than context continuity.
For self-hosted deployments, treat GPU utilization as a first-class metric. An ICSE 2024 study of 400 Microsoft internal deep learning jobs found average GPU utilization at 50% or below — idle GPUs at peak provisioning are pure waste. Three levers address this directly:
- Inference batching: vLLM has reported up to 24x throughput improvement over baseline Hugging Face Transformers
- Model quantization: INT8/INT4 formats can halve or quarter memory requirements, enabling more concurrent requests per GPU
- Reserved instances: GCP and AWS offer 55–72% discounts over on-demand pricing for predictable workloads
Conclusion
LLM cost control comes down to diagnosis before optimization. Cutting costs without identifying where they originate — at decision time, in production management, or in the surrounding architecture — risks sacrificing quality while leaving the real cost drivers untouched.
LLM cost optimization is a core function within LLMOps — the operational discipline of running LLMs reliably in production. This is ongoing work: model pricing changes, new tiers appear, architectural patterns evolve. Cost discipline needs to be built into how teams operate — not treated as a periodic audit.
FastRouter's LLMOps platform supports that by consolidating visibility across providers and surfacing attribution data by team and workload, alongside routing, evaluations, guardrails, and governance from a single control plane. Routing decisions can then match model cost to actual task requirements, making cost discipline easier to maintain at scale.
Frequently Asked Questions
How can I optimize LLM token usage to reduce costs?
Shorten system prompts, constrain output length via explicit instructions or max_tokens parameters, and use RAG to replace large context windows with targeted retrieval. Add semantic or native prompt caching to avoid reprocessing semantically similar queries — providers like OpenAI and Anthropic offer native caching that can reduce input costs by up to 90%.
What is the difference between LLM API costs and self-hosted GPU infrastructure costs?
API costs are variable and scale per token with no upfront commitment, making them predictable at low volume but expensive at scale. Self-hosted GPU costs are fixed compute expenses that require sustained high utilization to justify — and depend heavily on serving stack (vLLM vs. standard Transformers) and quantization discipline.
When should I use batch processing instead of real-time LLM inference?
Batch processing suits any workload that doesn't require an immediate response — document processing, data enrichment, report generation, content pipelines. Both OpenAI and Anthropic offer batch APIs at 50% of standard pricing, making this one of the simplest cost reductions available for non-interactive use cases.
How does model routing help reduce LLM costs?
Routing directs simple queries to smaller, cheaper models and reserves frontier models for complex requests. Most real-world query distributions skew toward simpler inputs, so even basic routing can cut average cost per request significantly — without degrading quality where it matters.
What is semantic caching and how much can it save?
Semantic caching stores prior model responses and returns them when a new query is sufficiently similar, using vector embeddings rather than exact-match logic. One documented case (Mangoes.ai via Redis LangCache) achieved a 70% cache hit rate and 70% LLM cost reduction. Actual savings depend on query overlap in your specific workload.
How do I track and attribute LLM costs across teams and use cases?
Native provider dashboards show aggregate spend but lack workload-level attribution. Tag API calls in your application layer with metadata by feature, team, or customer segment. FastRouter consolidates multi-provider billing into a single view with per-team cost reporting and dynamic request tagging — connecting spend directly to the workloads generating it.