Usage Analytics
Track token consumption, spend, and usage patterns across models and providers in one dashboard, helping teams understand where limits are reached and how workloads can be optimized.
Understand how LLM token limits affect request size, response length, cost control, and reliability across API workflows. This reference explains token policies, practical limits, routing considerations, monitoring, and governance features that help teams avoid truncation, failed calls, and unexpected usage spikes while managing multi-model AI applications more effectively.
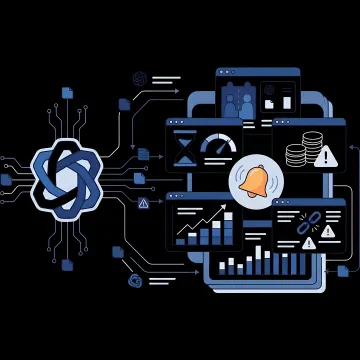
Tools and capabilities for managing token limits, usage visibility, routing decisions, and governance across AI APIs.
Track token consumption, spend, and usage patterns across models and providers in one dashboard, helping teams understand where limits are reached and how workloads can be optimized.
Set project and API key limits to prevent token overages, budget surprises, and uncontrolled model usage while keeping teams productive with clear governance guardrails.
Route requests to the most suitable model based on context window, latency, and cost so applications stay within token constraints without sacrificing performance.
Monitor request logs, latency, errors, and model behavior in real time to diagnose token-related failures, truncation issues, and provider-specific limit constraints.
Use automatic fallback and redundancy when a provider hits rate or token-related constraints, keeping applications available through healthy alternative models.
Validate inputs and outputs before requests are sent or returned, reducing malformed prompts, unsafe content, and inefficient payloads that waste token budgets.
LLM token limits shape how much context you can send, how long responses can be, and how reliably applications perform at scale. A strong API management approach helps teams monitor usage, control spend, route requests to models with the right context windows, and reduce failures caused by oversized prompts, truncation, or provider-specific constraints.
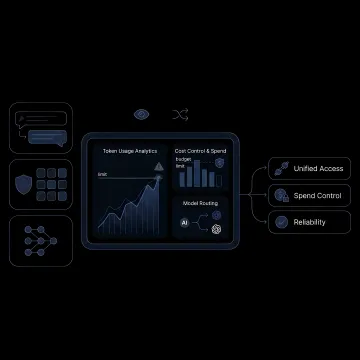
Capabilities that help teams control token usage, reliability, and model performance across production AI workloads.
"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."

"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."

"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."

"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."
"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."
"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."
"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."
"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."
"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."
Get a practical view of token limits and the systems used to manage them.
One API layer simplifies token management across many models and providers.
Project and key limits help prevent token overages and billing spikes.
Failover and redundancy reduce disruption when providers hit hard limits.
Logs, analytics, and alerts expose token usage trends and request failures.
Built for teams managing AI at scale.
This reference is grounded in the operational realities of modern AI API management. It focuses on how teams handle token limits across multiple providers, models, and production workloads without adding unnecessary complexity. Rather than treating token limits as an isolated constraint, the platform approach connects routing, observability, governance, billing, and reliability into one control layer. That means teams can compare context windows, monitor request behavior, set usage boundaries, and respond quickly when prompts exceed limits or providers enforce stricter caps. The broader goal is simple: make AI infrastructure easier to operate, easier to optimize, and more predictable as usage grows across applications, teams, and environments.
An LLM token limit policy defines how many tokens can be included in a request and generated in a response. It usually covers prompt size, context window constraints, output caps, and provider-specific enforcement rules. In practice, the policy helps teams prevent failed requests, truncated outputs, runaway costs, and performance issues by setting clear boundaries for how models are used in production.
Talk through your API management needs with our team.

Works with existing client integrations.
Controls access, limits, and oversight.
Failover and redundancy built in.
Share your API management questions and get practical guidance on token policies, routing, observability, and cost controls.
To help us assist you faster, please include the reason for your message so the relevant team can reach out as soon as possible.
To help us assist you faster, please include the reason for your message so the relevant team can reach out as soon as possible.