
For teams building AI products today, this distinction is practical, not academic. Enterprise AI spending reached $37 billion in 2025, up from $11.5 billion the year prior — yet 88% of AI pilots still fail to reach wide-scale deployment. The wrong operational framework contributes directly to that failure rate through runaway costs, model drift, and brittle deployments.
This article breaks down both disciplines — what they cover, where they diverge, and how to decide which one your team actually needs.
Key Takeaways
- MLOps manages traditional ML model lifecycles; LLMOps handles production demands unique to large language models
- The core difference is the nature of the output — structured predictions vs. open-ended generated text
- LLMOps introduces risks — prompt injection, hallucination, per-token costs — that standard MLOps tooling doesn't cover
- LLMOps is not a replacement for MLOps — it's a specialized extension for a different class of AI systems
- Most enterprise teams will need both, applied to different models within the same product
MLOps vs LLMOps: Quick Comparison
Both disciplines move AI from experimentation to reliable production, but the challenges they address and the tools they require differ significantly.
| Dimension | MLOps | LLMOps |
|---|---|---|
| Model Type | Smaller, task-specific models (XGBoost, CNNs) on structured data | Large pre-trained foundation models (GPT-4, Claude, LLaMA) |
| Primary Focus | Data pipelines, training, deployment, drift monitoring | Prompt management, inference, RAG, output evaluation, cost governance |
| Versioning | Datasets, feature sets, model weights, code | Prompts, embeddings, vector stores, fine-tuned variants |
| Monitoring Metrics | Accuracy, precision/recall, F1, AUC, data drift | Hallucination rate, relevance, latency per token, toxicity, cost per call |
| Key Tools | MLflow, Kubeflow, SageMaker Pipelines, Weights & Biases | LangChain, LlamaIndex, vLLM, Pinecone, vector DBs, LLMOps platforms |

What is MLOps?
MLOps — Machine Learning Operations — applies DevOps principles (automation, CI/CD, version control, monitoring) to the ML lifecycle, bringing together data scientists, ML engineers, and infrastructure teams under a shared operational framework to move models from experiment to reliable production deployment.
The Core MLOps Pipeline
The process is cyclical, not a one-time handoff:
- Data ingestion and validation — ingest raw data, check for schema drift or missing values
- Feature engineering — transform raw data into model-ready features, stored in a feature store
- Model training — train on versioned datasets with tracked hyperparameters
- Evaluation — compare against baseline metrics before promoting
- Deployment — package and serve the model via a CI/CD pipeline
- Monitoring and retraining — detect drift, trigger retraining when performance degrades
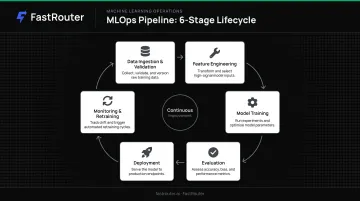
Without this structure, models degrade silently or become impossible to audit. MLOps solves for reproducibility, training-serving skew, and governance — the exact failure points that turn a working experiment into an undebuggable production incident.
Experiment Tracking and Model Registries
Tools like MLflow — which surpassed 10 million monthly downloads in 2022 — give teams a shared system for comparing training runs, storing model metadata, and promoting approved models to production with confidence. The MLOps market was valued at $2.19 billion in 2024 and is projected to reach $16.61 billion by 2030, reflecting how central this discipline has become.
Where MLOps Fits Best
MLOps excels at structured prediction problems where the expected output is a score, label, or number:
- Fraud detection in financial services, scoring transactions in real time against engineered features
- Predictive maintenance in manufacturing — one documented implementation hit 88% defect-prediction accuracy and saved $10–12M annually
- Churn prediction in SaaS products, retrained as new cohort data arrives
- Recommendation engines in e-commerce, updated continuously against behavioral signals
The improvement loop is straightforward: new labeled data arrives, drift alerts or a retraining schedule triggers a new training run, and updated model versions move through a CI/CD pipeline into production.
What is LLMOps?
LLMOps — Large Language Model Operations — is the set of practices, tools, and workflows that manage LLMs in production. It inherits core concepts from MLOps but addresses fundamentally different challenges: non-deterministic outputs, prompt sensitivity, GPU-heavy inference, and risks like hallucination or adversarial inputs.
A Different Development Flow
Most teams don't train LLMs from scratch. Instead, they customize pre-trained foundation models through:
- Prompt engineering — crafting instructions that guide model behavior
- Fine-tuning (LoRA/QLoRA) — adapting model weights on domain-specific data
- Retrieval-Augmented Generation (RAG) — grounding responses in retrieved enterprise content
This shifts engineering effort away from data pipelines toward prompt design, vector stores, and inference orchestration. The required skill set, toolchain, and iteration cycle all change as a result.
The Monitoring Challenge
LLM outputs are open-ended text. You can't summarize performance with a single accuracy score. LLMOps requires evaluation across multiple dimensions simultaneously:
- Relevance — does the response actually answer the question?
- Factual grounding — is the response supported by retrieved context?
- Toxicity — does it contain harmful content?
- Latency and cost — how much did that inference cost per token?
- Hallucination rate — one study found rates of 28.6% for GPT-4 and 39.6% for GPT-3.5 on reference tasks

These dimensions can conflict: a response that's fluent isn't always accurate. LLMOps addresses this through LLM-as-judge evaluation patterns and human-in-the-loop review alongside automated metrics.
Security and Compliance
LLMs introduce risks that traditional ML models don't face. OWASP's 2025 LLM risk list identifies prompt injection as a top threat, alongside sensitive information disclosure — where models leak PII, credentials, or financial data in their outputs. NIST similarly notes that GenAI systems may infer or expose sensitive information about individuals.
Guardrails and output filtering aren't optional in enterprise LLMOps deployments — they're baseline requirements.
What a Modern LLMOps Platform Does
An LLMOps platform unifies the operational layer that teams would otherwise need to build and maintain themselves:
- Routes requests across multiple LLM providers based on cost, latency, and quality
- Tracks experiments and prompt versions
- Enforces cost governance and spending caps
- Applies guardrails at the inference layer
FastRouter is an example of this kind of unified LLMOps control plane — an OpenAI-compatible single interface that handles multi-provider routing, observability, guardrails, and cost governance across 100+ models, without requiring teams to wire this infrastructure together themselves.
Where LLMOps Fits Best
LLMOps applies to any application that generates, summarizes, or reasons over natural language:
- Customer-facing chatbots and conversational assistants
- Document summarization in legal, compliance, or financial workflows
- AI-powered search and RAG-based Q&A over internal knowledge bases
- Coding assistants (GitHub Copilot-style deployments)
- Enterprise knowledge systems — Morgan Stanley embedded GPT-4 into advisor workflows, using evaluations to improve how advisors access the firm's knowledge base
The improvement loop here doesn't involve retraining the full model. They iterate on prompts, refresh the retrieval index, or apply parameter-efficient fine-tuning. Feedback comes from human evaluation, automated evals, and production traces.
Key Differences Between MLOps and LLMOps
LLMs behave differently from traditional ML models at a fundamental level. They're stochastic, context-sensitive, and capable of producing both excellent and harmful outputs from the same input — and that shapes every operational decision downstream.
Retraining vs. Iteration
In MLOps, improvement means retraining on fresher labeled data, triggered by a drift alert or a schedule. In LLMOps, "retraining" often means updating a prompt, refreshing a retrieval index, or applying PEFT (parameter-efficient fine-tuning) — each requiring different tooling and different skills. One arXiv study found output accuracy variation of up to 15% across runs even at temperature 0, which makes repeatability testing a core LLMOps requirement regardless of whether the model itself changes.
Deterministic vs. Multi-Dimensional Evaluation
MLOps evaluations are deterministic: run the test set, compute the metric, compare to threshold. LLMOps evaluations are inherently multi-dimensional and often subjective, measuring whether an answer is helpful, accurate, safe, and on-brand simultaneously. LLM-as-judge patterns help scale this evaluation, but the MT-Bench research flags known limitations including position bias and verbosity preference, which means human review remains part of the process.
Cost as an Operational Variable
Traditional ML inference is comparatively cheap. LLMs involve real per-token costs: GPT-4-class models run at $5–$30 per million tokens depending on the provider and configuration, while cheaper alternatives like Gemini Flash sit at $0.30 input / $2.50 output per million tokens.
At scale, that spread matters enormously. Cost governance and model routing become critical LLMOps concerns that barely register in standard MLOps workflows. FastRouter's audit data reports an average cost reduction of 46% identified through intelligent routing and cost controls.
Team Composition
MLOps teams are primarily data scientists and ML engineers. LLMOps broadens the operational surface to include prompt engineers, RAG architects, and product and UX stakeholders, because conversational quality is part of model performance. A 2025 arXiv study of 20,662 job postings found prompt engineers need a distinct mix of skills:
- AI and model knowledge
- Prompt design and iteration expertise
- Communication and stakeholder collaboration
- Creative problem solving
That's a meaningfully different profile from the ML engineer maintaining a churn model.
MLOps vs LLMOps: Which One Does Your Team Need?
- Use MLOps when the system returns a structured prediction (a score, class, or rank) from trained features — fraud detection, demand forecasting, classification, recommendation
- Use LLMOps when the system generates text, answers questions, or retrieves and synthesizes information for a user
Many enterprise teams will need both. An MLOps-managed churn model and an LLMOps-managed support chatbot can coexist in the same product, each governed by the framework appropriate to its risks.
Choose MLOps when:
- You control the training process end-to-end
- You have labeled data and a defined prediction target
- You need fully reproducible, auditable model outputs
- Performance is measurable with a single numeric metric
Choose LLMOps when:
- You're building on top of foundation models you don't train
- Output quality depends on prompts, retrieval, and context
- Your risk surface includes hallucination, prompt injection, or PII exposure
- You're managing inference costs across multiple providers
For teams landing in the LLMOps column, the operational surface expands quickly once you move past a single provider. Managing prompt versions, enforcing guardrails, controlling costs, and maintaining reliability across providers are ongoing tasks — not one-time setup. FastRouter addresses this as a unified control plane across 100+ models, handling routing, observability, cost governance, and guardrails in one place.
Conclusion
MLOps and LLMOps are complements, not competitors. They're built for different classes of AI systems — and the right choice depends on the type of model, the nature of the output, and the risks that matter most in production.
As organizations move from single-model deployments to hybrid AI architectures that combine predictive models and generative AI, having a clear operational framework for each becomes a real competitive advantage.
Teams that treat LLMOps as an afterthought tend to encounter the same problems: unpredictable costs, brittle deployments, and failures that are hard to debug. LLMs demand their own operational layer — one built around prompt versioning, token spend visibility, output evaluation, and provider redundancy rather than the retraining pipelines and feature drift monitoring that define traditional MLOps.
For teams running LLMs in production, a purpose-built platform like FastRouter handles the infrastructure side of that layer — routing across 100+ models, enforcing guardrails, tracking costs per request, and surfacing the observability data needed to catch issues before they compound.
Frequently Asked Questions
What exactly is LLMOps?
LLMOps (Large Language Model Operations) refers to the practices and tools used to manage LLMs in production — covering fine-tuning, prompt management, inference optimization, evaluation, cost governance, and output safety. It applies to any system built on foundation models like GPT-4, Claude, or Gemini.
What is MLOps in simple terms?
MLOps (Machine Learning Operations) is the practice of deploying and maintaining ML models reliably in production. It combines DevOps principles with the ML lifecycle to automate training, deployment, monitoring, and retraining — preventing silent model degradation and keeping results reproducible and auditable.
What is the difference between LLMOps and MLOps?
MLOps applies to traditional ML models, while LLMOps applies to large language models. The key differences are how models are updated (scheduled retraining vs. prompt and RAG iteration), how outputs are monitored, and the unique cost and safety risks LLMs introduce.
Is LLMOps a replacement for MLOps?
No. LLMOps is a specialized extension for teams working with large language models. Organizations running both traditional ML models and LLMs will use both frameworks in parallel, applying each to the appropriate system.
Do organizations need both MLOps and LLMOps?
Many enterprise teams do — for example, an MLOps-managed fraud detection model alongside an LLMOps-managed document summarization tool. The decision depends on which AI model types are in production and what operational risks each carries.


