Model Routing
Intelligently direct each request to the best-fit model using semantic intent, cost, latency, and output quality signals, reducing manual model selection and improving application performance.
Route every AI request with more context, less waste, and better outcomes. This page explains how semantic routing helps teams direct prompts to the right model, workflow, or provider based on meaning, intent, cost, latency, and reliability—so your AI stack stays faster, smarter, and easier to manage at scale.

Explore routing, reliability, governance, and optimization capabilities that help teams manage AI requests intelligently across models and providers.
Intelligently direct each request to the best-fit model using semantic intent, cost, latency, and output quality signals, reducing manual model selection and improving application performance.
Keep AI applications available during outages, rate limits, or model failures with automatic fallback lists and multi-provider redundancy that reroute traffic instantly.
Validate prompts and responses before they reach users, enforcing safety, compliance, and consistency while catching malformed outputs, policy violations, and risky content.
Monitor routing decisions, latency, errors, and provider performance through unified dashboards and logs that give teams clear visibility into AI workload behavior.
Reduce unnecessary spend by routing requests to efficient models, avoiding overuse of premium options, and applying smarter selection logic across providers.
Compare outputs across models to verify quality and consistency, helping teams refine routing policies and choose the right model for each task.
An LLM semantic router helps your application understand what a request is trying to accomplish, then sends it to the most appropriate model, provider, or workflow. Instead of relying on static rules alone, semantic routing improves quality, controls cost, reduces latency, and strengthens resilience with fallback logic, guardrails, and observability built around real production needs.
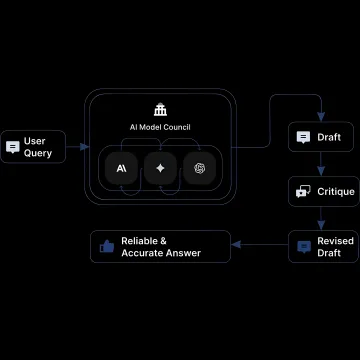
See how teams improve AI reliability, quality, and cost control with smarter routing.
"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."

"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."

"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."

"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."
"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."
"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."
"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."
"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."
"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."
FastRouter helps teams operationalize semantic routing with practical controls for production AI.
Connect to 150+ AI models through one OpenAI-compatible API integration.
Automatic failover and redundancy keep requests flowing during provider issues and rate limits.
Routing, limits, and billing visibility help prevent overspend across multi-provider AI usage.
Roles, access controls, and guardrails support safer, more consistent AI operations.
Built for teams scaling AI reliably.
FastRouter is focused on helping businesses use AI infrastructure more intelligently. The platform is built around a simple idea: teams should not have to choose between flexibility, reliability, and cost control when deploying LLM-powered products. By combining unified API access, semantic routing, failover, governance, observability, and billing consolidation, FastRouter gives organizations a more practical way to run multi-model AI in production. Its vision is to make advanced AI operations easier to manage for product, engineering, and platform teams—so they can test faster, route smarter, and maintain stronger control over quality, uptime, and spend as usage grows.
Semantic routing in AI is the process of analyzing the meaning or intent of an incoming request and sending it to the most appropriate model, tool, workflow, or provider. Instead of using only fixed keyword rules, it uses contextual understanding to improve response quality, reduce latency, control cost, and support better task-to-model matching in production systems.
Talk with our team about semantic routing and AI infrastructure.

Simplifies integration across AI providers.
Supports always-on AI operations.
Built for controlled AI usage.
Share your use case and we’ll help you evaluate the right routing, reliability, and governance approach for production.
To help us assist you faster, please include the reason for your message so the relevant team can reach out as soon as possible.
To help us assist you faster, please include the reason for your message so the relevant team can reach out as soon as possible.