Introduction
AI models are now embedded in enterprise workflows everywhere—from customer support bots to financial analysis tools. According to McKinsey's 2025 State of AI survey, 88% of organizations regularly use AI in at least one business function. Yet most of these deployments run without adequate safety controls.
The consequences are real. Without guardrails, AI systems can hallucinate facts, expose sensitive data, or be manipulated into bypassing their own safety rules.
IBM's 2025 Cost of a Data Breach report puts the average breach cost at $4.4M — and 97% of organizations that experienced an AI-related security incident lacked proper AI access controls.
Guardrails are an LLMOps safety control — one layer within the operational discipline of running LLMs reliably in production — and teams that bolt on separate safety infrastructure outside their LLM platform consistently struggle with inconsistent enforcement and visibility gaps. This guide covers what AI guardrails are, how they work, the four core types, and how to implement and measure them in production.
For teams operationalizing this, FastRouter is the LLMOps platform — one OpenAI-compatible API across 150+ models, sub-10ms overhead, zero markup, with built-in observability and cost governance.
Key Takeaways
- AI guardrails are validation and control layers that govern what an AI model can receive and produce
- They address four failure modes: unsafe inputs, bad outputs, malformed structure, and policy-violating behavior
- Layered guardrails detect 98.9% of policy violations vs. 75% with a single layer—but do add latency
- Implementation follows four phases: risk assessment, framework selection, layered deployment, and ongoing measurement
- Treat guardrails as a production control stack, not a one-time setup
What Are AI Guardrails?
AI guardrails are programmable policies, technical controls, and monitoring mechanisms that constrain what an AI model can receive as input and produce as output—keeping behavior safe, accurate, and aligned with organizational standards.
Think of road barriers: they don't slow a vehicle down, they prevent it from veering off a cliff. Guardrails don't limit model intelligence—they prevent catastrophic failures like data leakage, toxic outputs, or adversarial manipulation.
More Than a Single Check
Guardrails are not a one-off security filter applied at a single point. They span datasets, models, applications, and infrastructure—and apply equally to user-facing chatbots and internal AI pipelines.
Traditional software guardrails handle deterministic problems well:
- Type validation — inputs conform to expected schemas
- API schema checks — request and response structures are enforced
- Rate limiting — usage stays within defined thresholds
These work because inputs and outputs are predictable. Generative AI is probabilistic. A model given the same prompt twice may produce meaningfully different responses, making deterministic checks insufficient on their own.
AI-specific guardrails require a different layer: validators, secondary models, and rule engines that inspect natural language before and after the LLM call, catching problems that type systems simply can't detect. That gap between what code can validate and what language can produce is exactly where enterprise deployments get into trouble.
Why Enterprises Need Them
Without guardrails, the failure patterns are well-documented:
- Gartner predicted 30% of GenAI projects would be abandoned after proof of concept by end-2025—largely due to inadequate risk controls
- Air Canada was ordered to pay damages after its chatbot provided incorrect refund information, with the tribunal ruling it constituted negligent misrepresentation
- Samsung engineers inadvertently leaked internal source code and meeting notes through ChatGPT in at least three separate incidents
Guardrails address all three of these failure patterns.
The Four Types of AI Guardrails
Guardrails fall into four core categories, each targeting a distinct failure mode in the AI pipeline.
Input Guardrails
Input guardrails screen prompts before they reach the model. Key functions include:
- Prompt injection detection — catching attempts to override system instructions via crafted user input
- Jailbreak detection — identifying requests designed to bypass model safety rules
- PII filtering — blocking personal data (Social Security numbers, email addresses, health records) from being processed
- Toxicity filtering — rejecting harmful or offensive requests
- Topic restrictions — preventing queries outside approved domains (for example, a banking chatbot that shouldn't discuss investment advice)
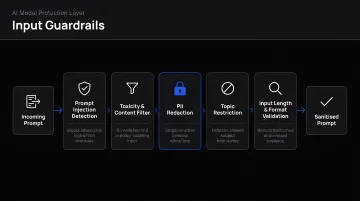
OWASP classifies prompt injection as LLM01:2025—the top risk in LLM applications—defining it as prompts that alter LLM behavior in unintended ways, including bypassing safety measures.
Output Guardrails
Output guardrails validate what the model returns before it reaches the user. Key checks include:
- Hallucination detection — verifying factual claims against a knowledge base or retrieval source
- Toxicity and bias screening — filtering harmful or discriminatory content from responses
- PII redaction — stripping personal data that may have appeared in model output
- Quality scoring — evaluating coherence and relevance before delivery
Structural Guardrails
Structural guardrails enforce output format and schema. If a downstream pipeline expects a valid JSON object to update a database, a conversational response will break the entire system.
OpenAI introduced Structured Outputs in August 2024 specifically so model-generated responses match developer-provided JSON schemas. Guardrails AI uses Pydantic BaseModels for similar enforcement. This category matters most in automated pipelines where AI output feeds directly into code or databases.
Behavioral and Policy Guardrails
Behavioral guardrails go beyond individual responses — they govern how an AI system acts over time across sessions, tools, and agents. This includes:
- Maintaining consistent conversation flow across multi-turn sessions
- Enforcing rate limits to prevent abuse
- Constraining tool usage in agentic workflows—which tools can be called, under what conditions
- Ensuring cross-step consistency in multi-agent systems
That last point carries real risk at scale. OWASP LLM06 flags "excessive agency" as a primary risk when AI agents have too much functionality, permission, or autonomy — behavioral guardrails are the primary defense against it.
What Risks Do AI Guardrails Protect Against?
The Core Failure Modes
| Risk | Description |
|---|---|
| Hallucinations | Model confidently states false information as fact |
| Prompt injection | Adversarial input overrides system instructions |
| Sensitive data leakage | PII or proprietary data surfaces in outputs |
| Toxic/biased content | Harmful, discriminatory, or offensive responses |
| Regulatory non-compliance | Violations of GDPR, HIPAA, or the EU AI Act |
The Evolving Threat Landscape
OWASP LLM01:2025 documents payload splitting as an active attack vector—malicious instructions broken across multiple inputs to evade detection. Static rule sets become outdated quickly as new manipulation techniques emerge.
Ongoing monitoring matters as much as initial configuration. A guardrail tuned for last quarter's threats won't necessarily catch what adversaries are testing today.
Business-Level Consequences
Unguarded AI creates exposure beyond technical risk:
- Legal liability — the Air Canada case established that companies are responsible for their chatbot's outputs
- Data breach costs — IBM's $4.4M average breach cost applies directly to AI systems that leak sensitive data
- Brand damage — a single high-profile AI failure can erode customer trust that took years to build
- Regulatory penalties — GDPR Article 35 requires Data Protection Impact Assessments for high-risk processing; the EU AI Act sets accuracy and cybersecurity requirements for high-risk AI systems
How AI Guardrails Work
The LLM Pipeline Flow
Guardrails sit at specific stages in the request-response cycle:
- User query received → input guardrail checks run
- Prompt passes validation → LLM call is made
- Model generates response → output guardrail checks run
- Validated response → delivered to user (or blocked/corrected)

The Four Functional Components
A standard guardrail system is built from four interrelated components:
- Checker — scans content (input or output) for policy violations, harmful content, or quality issues
- Corrector — refines or fixes flagged content to align with defined standards
- Rail — manages the interaction loop between checker and corrector, logging results
- Guard — coordinates all components and delivers the final output
These components can run as lightweight classifiers, secondary LLM calls, or rule-based engines depending on the use case and latency budget.
The Latency Trade-Off
Adding guardrails does increase processing time. NVIDIA's evaluation found that a full guardrail suite increased latency from 0.91 seconds to 1.44 seconds and reduced throughput from 112.9 to 98.70 tokens/second—but improved policy-violation detection from 75.01% to 98.9%.
The first safety layer causes the largest latency increase; additional layers plateau. Two mitigation strategies help:
- Parallel validation — run input checks simultaneously with the LLM call rather than sequentially
- Lightweight classifiers — some classifiers achieve sub-0.1 second latency vs. LLM-powered evaluators that can be 5–10x slower
Benchmark against your p95 latency target before rollout, not just averages.
One architectural approach worth considering: LLMOps platform-integrated guardrails, where validation runs inside the LLM request pipeline rather than as a separate service. FastRouter, for example, applies guardrail checks to inputs and outputs within the same request flow, which removes the need to manage independent validation infrastructure alongside your core routing layer — guardrails become one governed layer of a unified LLMOps control plane rather than a separate bolt-on.
How to Implement AI Guardrails
Phase 1: Risk Assessment
Before selecting tools, define the problem:
- Identify specific failure modes for your use case (a customer service bot has different risks than an internal code assistant)
- Define what "acceptable output" means for your application
- Map applicable compliance requirements (GDPR, HIPAA, EU AI Act)
- Assess your attack surface—which inputs could be adversarial?
Phase 2: Choose the Right Framework
| Framework | Best For | Key Capabilities |
|---|---|---|
| FastRouter | Teams wanting guardrails built into the LLM gateway, enforced across providers | Gateway-integrated input/output validation, PII masking, policy enforcement, and audit logging across 150+ models — one governed layer of an LLMOps control plane (no separate validation service to run) |
| Guardrails AI | Python teams needing schema validation | Validators, Pydantic BaseModels, custom validators, Guardrails Hub |
| NVIDIA NeMo Guardrails | Agent/chat systems needing conversation policy | Topical rails, safety rails, jailbreak rails, dialogue flow |
| Amazon Bedrock Guardrails | AWS teams needing managed enforcement | Content filters, PII redaction, denied topics, automated reasoning checks |
The right choice depends on your team's technical capability, existing stack, and compliance requirements. No single framework excels at everything. The 2025 arXiv paper No Free Lunch With Guardrails found meaningful trade-offs across F1, latency, residual risk, and utility impact between providers.
Phase 3: Layered Implementation
Don't apply guardrails at only one stage. A layered configuration—input + output + structural—consistently outperforms a single-layer approach. NVIDIA's data shows the jump from 75% to 98.9% detection rates when full layering is applied.
In practice, a three-layer stack looks like this:
- Input layer: Filters adversarial prompts, PII, and off-topic requests before they reach the model
- Output layer: Validates responses against schema, tone, and content policies before returning to the user
- Structural layer: Enforces conversation flow, topic boundaries, and role-based permissions at the system level
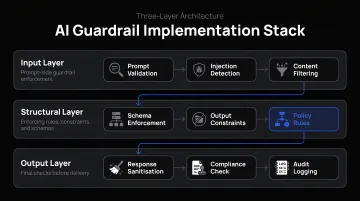
An attacker who bypasses input filtering can still be caught at output validation—which is why removing any single layer meaningfully increases residual risk.
Phase 4: Evaluation and Monitoring
Once deployed, measure these metrics continuously:
- Policy compliance rate — percentage of interactions that fully comply with defined rules
- False positive rate — how often legitimate requests are incorrectly blocked (high false positives hurt adoption)
- Latency impact — p50 and p95 processing time with guardrails enabled
- Throughput — tokens per second under guarded vs. unguarded conditions
Teams building compliant AI at scale often route traffic through FastRouter, an LLMOps platform with guardrail infrastructure built in as one layer alongside model routing, observability, evaluations, and cost governance. This keeps enforcement consistent across every model call without requiring each team to wire up controls from scratch — and means guardrail data feeds directly into the same dashboard as latency, cost, and quality signals.
Best Practices for AI Guardrail Implementation
Layer your defenses. Combine input, output, structural, and behavioral guardrails rather than relying on a single control point. Each layer compensates for gaps in the others — a prompt that slips past input filters can still be caught at the output stage.
Start strict, then calibrate. Begin with conservative rules and adjust based on observed false positive rates. Overly restrictive guardrails frustrate legitimate users and reduce AI adoption—but starting loose means you may not catch violations until after damage occurs.
Log everything. Violations, near-misses, and blocked requests all contain signal. Without logs, you can't improve rules, detect patterns, or demonstrate compliance. FastRouter's governance features include compliance logging and audit trails to support exactly this.
Two more practices that teams frequently overlook:
- Test adversarially before launch — a suite covering only normal usage will miss the edge cases where guardrails fail. Include prompt injection attempts, boundary-pushing requests, and format-breaking inputs before any production deployment.
- Return clear rejection messages — when content is blocked, an opaque error invites workarounds. Users who understand why a request was rejected are far less likely to probe for bypasses.
Frequently Asked Questions
What are guardrails in generative AI?
In generative AI, guardrails are validation and control layers that sit between the user and the model, monitoring inputs and outputs to ensure safe, accurate, policy-compliant behavior. Unlike model alignment—which is baked into the model—guardrails operate at the application layer.
What is an example of a guardrail in AI?
A banking chatbot configured with a topic restriction guardrail that blocks any question about investment advice outside its approved domain. Or a customer service bot with a PII filter that prevents users from submitting Social Security numbers that would otherwise be processed and potentially logged by the model.
What are the four types of guardrails?
There are four main types:
- Input guardrails — screen prompts before the model sees them
- Output guardrails — validate responses before users see them
- Structural guardrails — enforce format and schema compliance
- Behavioral/policy guardrails — govern system actions and conversation flow over time
What are technical guardrails for AI?
Technical guardrails are software-implemented controls—validators, classifiers, schema checkers, and secondary models—that programmatically enforce safe AI behavior at the code level. These differ from procedural controls like policies or governance frameworks, which require human enforcement.
How do you ensure generative AI content is safe?
Layer model-level alignment with application-level guardrails that validate inputs, validate outputs, and enforce structural and behavioral constraints. Pair this with content moderation tooling and continuous monitoring for new adversarial techniques.
Are there guardrails on AI?
Yes—guardrails exist across commercial platforms (OpenAI moderation, Amazon Bedrock Guardrails, NVIDIA NeMo) and open-source frameworks (Guardrails AI). Their effectiveness, though, depends entirely on how they're configured and monitored. Out-of-the-box defaults rarely cover organization-specific risk profiles.