Model Evaluations
Systematically compare outputs across models to measure quality, consistency, latency, and cost, helping teams choose the right model for each production use case.
Assess, monitor, and govern generative AI applications with services designed to improve output quality, control spend, strengthen reliability, and enforce policy. From model evaluations and guardrails to observability, routing, and audit support, this page outlines practical ways teams can deploy AI more confidently in production.
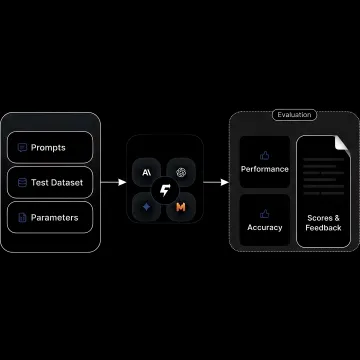
Comprehensive services for evaluating model performance, enforcing controls, and improving visibility across production generative AI systems.
Systematically compare outputs across models to measure quality, consistency, latency, and cost, helping teams choose the right model for each production use case.
Validate prompts and responses to catch unsafe content, policy violations, and malformed outputs before they reach users or downstream systems.
Audit live AI requests to uncover savings opportunities, reliability gaps, and performance tradeoffs, then use the findings to improve routing and governance decisions.
Track AI activity with unified dashboards, logs, and metrics so teams can monitor latency, errors, usage patterns, and model behavior over time.
Apply project limits, API key restrictions, member roles, and access controls to manage spend, reduce misuse, and standardize model access across teams.
Monitor uptime, latency, and output quality in real time to detect regressions early and maintain dependable AI application performance.
These services help organizations move beyond basic model access and build disciplined AI operations. By combining evaluations, guardrails, monitoring, audit workflows, and governance controls, teams can improve output quality, reduce unnecessary spend, strengthen uptime, and create clearer accountability for how generative AI is used across applications, departments, and production environments.
See how teams improve AI quality, control costs, and strengthen governance with structured evaluation services.
"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."

"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."

"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."

"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."
"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."
"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."
"Excellent platform to test the latest LLMs for our use case. With new LLMs coming out every few weeks and benchmarks not giving the full picture, I rely on Fastrouter.ai to optimize my cost vs quality balance."
"Amazing product. Have had a great experience using FastRouter. Reliable access to models across providers helps removes the worry about outages or vendor lock-in."
"FastRouter is a good value add, specifically when you are not sure which LLM is better for your use cases. You can play around with models, can compare against them, and then use normal OpenAI compatible APIs call to leverage the full potential of it."
FastRouter combines evaluation depth with practical governance controls for production AI teams.
Manage evaluations, routing, guardrails, and spend controls from one connected AI operations layer.
Real-time logs, metrics, and alerts help teams spot regressions before they affect users.
Roles, limits, and access controls support safer model usage across teams and applications.
Compare providers, route intelligently, and avoid lock-in as requirements evolve over time.
Focused on reliable, accountable AI operations.
FastRouter supports organizations that need more than simple model access. Its service approach centers on helping teams evaluate model performance, govern usage, and operate generative AI applications with greater confidence. By combining routing, observability, audit capabilities, guardrails, and cost controls, FastRouter helps businesses create a more disciplined foundation for production AI. The broader vision is practical and measurable: give teams the tools to compare models intelligently, enforce policies consistently, reduce operational surprises, and maintain visibility across providers. For organizations building internal tools, customer-facing applications, or AI-enabled workflows, that means a clearer path to safer adoption, better performance, and more accountable decision-making at scale.
Generative AI governance is the set of policies, controls, and monitoring practices used to manage how AI models are selected, accessed, evaluated, and used in production. It typically includes access controls, audit trails, guardrails, logging, spend limits, and performance oversight so organizations can reduce risk, improve consistency, and maintain accountability across teams and applications.
Talk with our team about evaluation, controls, and production oversight.

Built for controlled enterprise AI usage.
Supports resilient AI operations across providers.
Improves visibility into AI workloads.
Share your current AI setup, evaluation goals, or governance challenges, and we’ll outline practical next steps.
To help us assist you faster, please include the reason for your message so the relevant team can reach out as soon as possible.
To help us assist you faster, please include the reason for your message so the relevant team can reach out as soon as possible.