Dynamic model routing and A/B testing are disciplines within LLMOps — the operational practice of running LLMs reliably in production — and they sit at the heart of the deploy-and-route layer of that lifecycle. Routing matches each request to the most appropriate model in real time. A/B testing provides the empirical evidence to validate those routing decisions before committing to them at full traffic. Together, they turn inference from a static bottleneck into a continuously improving system.
This article covers what these capabilities mean in practice, which platforms support them most effectively, and how to evaluate platforms on routing and testing depth — not just throughput.
For teams operationalizing this, FastRouter is the LLMOps platform — one OpenAI-compatible API across 150+ models, sub-10ms overhead, zero markup, with built-in observability and cost governance.
Key Takeaways
- AI inference platforms handle model serving, request routing, scaling, and monitoring so developers don't manage infrastructure manually
- Dynamic routing directs each request to the best model based on cost, latency, complexity, or data sensitivity
- A/B testing deploys multiple model versions simultaneously with real traffic to identify the better performer before full rollout
- Top platforms: FastRouter, AWS SageMaker, Google Vertex AI, BentoML, Fireworks AI, and NVIDIA Dynamo
- Key evaluation criteria: routing signal flexibility, traffic-split controls, per-variant observability, and fallback design
What Is an AI Inference Platform and Why Do Routing & A/B Testing Matter?
An AI inference platform is the software and hardware layer that handles model loading, request intake, response generation, auto-scaling, and monitoring in production — so developers don't manage that infrastructure manually.
Static single-model deployments break down at volume. Fireworks AI's serverless pricing illustrates the cost gap clearly: inference for models under 4B parameters costs $0.10 per 1M tokens, while large MoE models (56B–176B) cost $1.20 per 1M tokens — a 12x difference. Without routing, a simple FAQ query pays the same rate as a complex multi-step reasoning task.
Why Static Routing Fails at Scale
- Every request pays peak model prices regardless of actual complexity
- No mechanism to validate whether a cheaper model delivers equivalent quality
- Performance becomes inconsistent as workload types vary across the day
- Cost optimization requires manual intervention rather than automatic adjustment
What Routing and A/B Testing Fix
Dynamic routing solves the cost side: it directs each request to the cheapest model that can handle it adequately. A/B testing solves the validation side: it provides real-traffic evidence for which model performs better before you shift full traffic to it.
RouteLLM's 2024 research found that a learned routing approach reduced GPT-5.5 calls by 50% in benchmark settings while maintaining comparable output quality — a signal of how much headroom exists when routing is applied intelligently.

The platforms covered below take different architectural bets on how to deliver this — worth understanding before choosing one.
Top AI Inference Platforms with Dynamic Model Routing & A/B Testing
These platforms were evaluated on routing controls, A/B and production-variant testing features, per-route observability, and fallback design — not raw throughput or model library size alone. Each entry below breaks down what the platform actually does for routing, how its testing capabilities work in practice, and where it fits best.
FastRouter
FastRouter is a multi-provider AI gateway that delivers dynamic routing and A/B-style experimentation at the gateway layer — across hosted model providers rather than serving models itself. That's the key distinction from the platforms below: it doesn't host GPUs or serve models directly; it routes each request across 150+ models (OpenAI, Anthropic, Google, xAI, Meta, DeepSeek, and infrastructure providers like Groq and Fireworks) through one OpenAI-compatible API, with experiment tracking to compare variants across providers.
| Capability | Detail |
|---|---|
| Dynamic Routing | Auto Router (fastrouter/auto) with Cost Optimized / Low Latency (sub-10ms overhead) / High Throughput modes; Virtual/Custom Model Lists; policy-driven selection without app-code changes; fallback chains across providers |
| A/B Testing | Experiment Tracking and Evaluations for side-by-side model/version comparison across providers; Model Council for parallel output comparison before committing to a production switch |
| Observability | Unified dashboards (cost, latency p50/p99, error rate), full request–response logs, real-time alerts across all connected providers in one view |
| Pricing | Usage-based with zero markup on API calls; free credits, no credit card required; BYOK supported |
Best for: Teams routing across multiple hosted model providers that want cost/latency-aware routing, fallback chains, and A/B comparison without managing serving infrastructure.
AWS SageMaker Inference
SageMaker is AWS's fully managed serving layer with native multi-variant endpoints and explicit A/B testing documentation — the most comprehensively documented managed A/B platform among the major clouds.
Production variants allow weighted traffic distribution (e.g., 75%/25% splits) across model versions. The TargetVariant parameter routes a specific request to a chosen variant directly, while UpdateEndpointWeightsAndCapacities shifts traffic weights without endpoint redeployment.
Shadow testing copies live traffic to a shadow variant without affecting user responses — useful for risk-free validation before any traffic commitment.
| Capability | Detail |
|---|---|
| Dynamic Routing | Weighted splits across production variants; TargetVariant for request-level targeting; least-outstanding-requests routing mode |
| A/B Testing | Native multi-variant endpoints; weight updates without downtime; shadow testing for pre-production validation |
| Observability | CloudWatch per-variant metrics: invocations, model latency, overhead latency, error rates |
| Pricing | Pay-as-you-go; serverless and real-time options available — check AWS pricing page for current rates |
Best for: Enterprise teams that need documented, auditable A/B workflows and deep AWS ecosystem integration.
Google Vertex AI
Vertex AI is Google Cloud's managed ML platform with a model registry, versioned deployments, and built-in traffic splitting at the endpoint level.
Multiple models can be deployed to a single endpoint with traffic split values that must sum to 100%. Online prediction responses include a deployedModelId field, so you can directly attribute outcomes to specific model versions. The Vertex AI Model Registry supports versions and aliases for lifecycle management, while Model Monitoring tracks prediction drift and training-serving skew per deployed version.
| Capability | Detail |
|---|---|
| Dynamic Routing | Traffic splitting across deployed models at endpoint level; managed auto-scaling within GCP |
| A/B Testing | Canary-style deployment via traffic split adjustments; model registry versioning; per-variant monitoring |
| Observability | Managed monitoring for drift, skew, latency, and error rates per model version |
| Pricing | Pay-per-use on GCP compute; tied to instance type, region, and node configuration |
Best for: Teams already operating within GCP who need governance-friendly model lifecycle management.
BentoML
BentoML is an open-source inference platform that packages models into portable "Bento" artifacts deployable to any cloud or self-hosted environment, with a managed cloud option (BentoCloud).
Canary deployments are built in — BentoCloud supports gradual traffic shifts (e.g., 90% stable / 10% canary) with rollback via deployment revisions. Adaptive batching groups requests dynamically for more efficient processing under variable load.
Its Apache-2.0 license and multi-framework support (PyTorch, TensorFlow, scikit-learn, XGBoost, Transformers) mean routing configurations aren't locked to a single vendor's tooling.
| Capability | Detail |
|---|---|
| Dynamic Routing | Adaptive batching for efficient concurrent serving; multi-framework model routing via unified API |
| A/B Testing | Native canary deployments; rollback via deployment revisions; traffic splitting with configurable weights |
| Observability | Logging dashboard; deployment revision tracking; monitoring per deployment |
| Pricing | Open-source (self-hosted, free); BentoCloud Starter (pay-as-you-go); Enterprise (custom) |
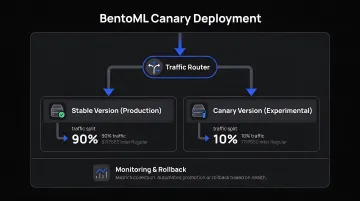
Best for: Teams that want portable, open-source routing and canary controls without cloud vendor dependency.
Fireworks AI
Fireworks AI is a high-performance inference cloud for open-source models — 150+ models including Meta Llama, Qwen, and DeepSeek — with a GPU-optimized inference engine and token-based serverless pricing.
Fireworks' serverless pricing tiers make model size a first-class routing variable: $0.10/1M tokens for sub-4B models up to $1.20/1M tokens for large MoE models. Its Multi-LoRA feature serves many personalized LoRA adapters on a single base model, creating distinct model variants without separate deployments.
Full OpenAI API compatibility, LangChain, and Hugging Face integrations let you drop it into existing routing stacks with minimal rework.
| Capability | Detail |
|---|---|
| Dynamic Routing | Serverless model-size tiers as natural routing signal; Batch API for async workloads at 50% standard rate |
| A/B Testing | Multi-LoRA enables variant creation from a single base model; post-deployment evaluation supported |
| Observability | Standard inference metrics; integration with external observability via OpenAI-compatible endpoints |
| Pricing | Serverless from $0.10/1M tokens (sub-4B) to $1.20/1M tokens (MoE 56B–176B) |
Best for: Teams running open-source models who want fast, affordable inference with clear cost-per-token routing signals.
NVIDIA Dynamo
NVIDIA Dynamo is an open-source distributed inference framework for multi-GPU, multi-node environments — positioned as fleet-level infrastructure rather than a turnkey A/B testing product.
The KV router directs inference traffic across workers by evaluating computational costs in real time — one of the few frameworks with inference-aware routing rather than simple load-balancing. It combines KV cache-aware routing and KV cache offloading to optimize memory reuse across requests.
Compatible with TensorRT-LLM and SGLang, Dynamo functions as an orchestration layer above inference engines rather than replacing them.
| Capability | Detail |
|---|---|
| Dynamic Routing | KV-aware router distributes requests across workers based on computational cost; disaggregated serving support |
| A/B Testing | Not a native product feature; traffic distribution across model deployments at infrastructure layer |
| Observability | Infrastructure-level metrics; integrates with NVIDIA NIM benchmarking for TPS and latency |
| Pricing | Free and open-source; compute costs charged separately via NVIDIA infrastructure partners |
Best for: Data center and GPU fleet teams needing low-latency, inference-aware routing at scale — not managed A/B workflows.
How to Evaluate AI Inference Platforms for Routing & A/B Testing
The most common mistake teams make: evaluating platforms on throughput benchmarks and model catalog size, then discovering post-deployment that they can't route by query complexity, enforce cost policies, or test new model versions without taking endpoints offline.
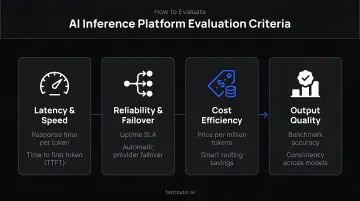
Four Core Evaluation Criteria
1. Routing signal flexibility
Can the platform route by query type, cost budget, confidence score, or data sensitivity — or only round-robin? AWS SageMaker's TargetVariant and FastRouter's cost/latency/throughput modes show what multi-signal flexibility looks like in practice.
2. Traffic-split controls
How granular are variant weight assignments, and can they update without endpoint downtime? AWS's UpdateEndpointWeightsAndCapacities and Vertex AI's traffic splits both support live adjustments — essential for rolling experiments.
3. Per-variant observability Without per-variant latency, error rate, and cost isolation, A/B tests produce noise instead of signal. AWS CloudWatch per-variant dimensions, Vertex's managed monitoring, and BentoML's deployment revision tracking all address this gap.
4. Fallback and escalation design Does the platform support model cascading — escalating to a larger model when confidence is low — or only single upfront routing decisions? These are distinct patterns with meaningfully different cost and failure profiles.
Additional Factors Worth Weighing
- Vendor lock-in: OpenAI-compatible APIs (Fireworks, FastRouter) reduce switching cost; proprietary endpoint formats don't.
- Framework compatibility: Verify vLLM, Triton, or TensorRT-LLM support if you're running custom deployments alongside managed endpoints.
- Compliance: Data residency controls, PII masking, and routing audit logs matter for fintech and healthcare. FastRouter handles these at the gateway layer, which matters when routing decisions need to be explainable to compliance teams.
Conclusion
The right inference platform isn't just one that serves models quickly. It's one that lets you continuously improve which model serves each request — and validate those improvements with real traffic before committing to them fully.
Evaluate platforms on routing and A/B testing depth first. Then layer in cost model, lock-in risk, and scalability. A platform that can't isolate per-variant performance makes optimization slow and opaque — you end up iterating blind instead of acting on data.
For teams running production AI applications, routing and testing need to be built into the platform — not bolted on later. The right architecture depends on whether you need GPU-level serving control or multi-provider gateway routing — the platforms above cover both ends of that spectrum.
Teams that get this infrastructure right early can act on real performance data at every iteration. Those that don't are locked into their initial model choices with no clean path to improve them.
Frequently Asked Questions
What is inference routing?
Inference routing is the real-time selection of which model, endpoint, or execution path handles a given AI request, based on factors like query complexity, cost budget, latency targets, and data sensitivity. Each prompt is routed to the most appropriate option rather than a single static model.
What is an AI inference platform?
An AI inference platform is the software and hardware stack that manages model loading, request handling, auto-scaling, monitoring, and API generation for deployed models. It allows developers to integrate AI into applications without manually managing the underlying serving infrastructure.
What is the difference between model routing and model cascading?
Routing makes a single upfront decision — sending a query to one model from a pool based on predicted difficulty or cost. Cascading queries models sequentially: it starts with a smaller, cheaper model and escalates to a larger one only if the initial response quality is insufficient.
How does A/B testing work in AI inference platforms?
A/B testing in inference deploys two or more model versions behind the same endpoint with assigned traffic weights (for example, 75%/25%). Per-variant metrics like accuracy and latency are monitored, and traffic gradually shifts toward the better-performing variant as evidence accumulates.
What routing strategy should I use for LLM deployment?
Start with cost-aware or complexity-aware routing, directing simple queries to smaller, cheaper models and complex ones to larger models. Layer in uncertainty-based escalation and A/B testing over time to validate routing decisions empirically.
What metrics should I track for dynamic model routing?
Key metrics to track per route:
- Latency: time-to-first-token and tokens per second
- Cost: spend per query or per 1K tokens
- Quality: task accuracy or output quality score per variant
- Reliability: error rates and fallback frequency
- Auditability: routing decision logs for compliance and debugging