For AI engineers, platform architects, and engineering leads building production AI systems, this matters more as infrastructure scales. Ad-hoc integrations — one provider hardcoded here, another patched in there — become brittle fast. Costs spike unpredictably. A single provider outage takes down your whole product. Routing is the operational layer that makes multi-provider AI infrastructure manageable instead of chaotic.
This guide covers what multi-provider LLM routing is, why teams adopt it, how the core strategies work, what factors shape routing decisions in production, and where implementations commonly break down.
For teams operationalizing this, FastRouter is the LLMOps platform — one OpenAI-compatible API across 150+ models, sub-10ms overhead, zero markup, with built-in observability and cost governance.
Key Takeaways
- Multi-provider LLM routing sends each request to the most appropriate model based on task complexity, cost targets, and latency requirements
- The two primary strategies are static routing (rule-based, predetermined) and dynamic routing (real-time classification via LLM classifiers or semantic similarity)
- Key benefits: lower inference costs, higher resilience through failover, and better output quality through task-model matching
- Routing decisions hinge on prompt characteristics, model capabilities, infrastructure dependencies, and cost-quality trade-offs
- Common pitfalls: treating routing as load balancing, ignoring classifier overhead, and applying it to use cases that don't need it
What Is Multi-Provider LLM Routing?
Multi-provider LLM routing is a traffic management layer that intercepts outgoing AI requests and decides — at runtime or by configuration — which LLM provider and model endpoint should handle each request.
The key word is intercepts. This is different from a developer manually switching between provider APIs in application code. A proper routing layer sits between the application and all downstream providers, making decisions transparently so the calling application doesn't need to know which model handled a given request.
How It Differs from Related Concepts
Three concepts are often conflated here:
| Concept | What It Does | Key Distinction |
|---|---|---|
| LLM Routing | Directs each request to the most appropriate provider/model | Selects based on content, cost, and context |
| Model Ensembling | Combines responses from multiple models | Runs multiple models simultaneously, merges outputs |
| Simple API Failover | Activates a backup when the primary fails | Only reactive; no intelligence about which model fits best |
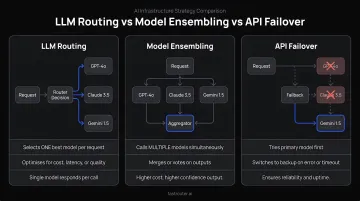
Routing handles the assignment problem: which model fits this specific request? Ensembling is about combining outputs from multiple models running in parallel. Failover only reacts when something breaks. A well-built routing layer can incorporate failover logic, but that's a subset of what routing does — not the whole picture.
The goal is that every request reaches the provider best suited to handle it, given cost, latency, availability, and domain fit.
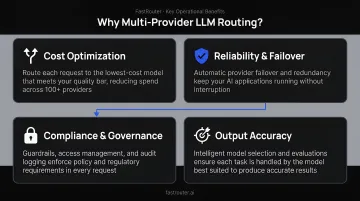
Why Organizations Adopt Multi-Provider LLM Routing
No single LLM performs optimally across all task types, complexity levels, and domains. According to a16z's 2025 CIO survey, 37% of enterprise CIOs are already using five or more models across experimentation and production workloads. As model diversity grows, a structured routing layer moves from nice-to-have to necessary infrastructure.
What Production Environments Demand
Routing addresses four distinct operational pressures:
- Cost predictability — routing simple tasks (classification, extraction, summarization) to cheaper models avoids paying frontier pricing for requests that don't need it. FastRouter's audit data shows teams typically waste 40%+ of their AI budget on unnecessary premium model usage, with an average achievable cost reduction of 46%
- Reliability — automatic failover to a secondary provider when the primary hits an outage or rate limit. OpenAI experienced significant downtime across all services in December 2024, including a separate four-hour outage later that month — teams with a single-provider dependency absorbed the full impact
- Compliance — routing sensitive data only to approved providers, enforcing GDPR processor requirements or HIPAA BAA constraints at the infrastructure level
- Domain accuracy — sending specialized queries to fine-tuned or domain-specific models rather than forcing a general model to handle everything
What Goes Wrong Without Routing
Each of these pressures compounds when teams hardcode a single provider:
- Switching providers requires code changes across the entire application — no abstraction layer means the vendor is woven into every integration point
- Usage growth hits expensive models uniformly, even for trivial requests, causing cost spikes that are difficult to forecast or control
- Provider outages become product outages with no automatic recovery path
- General models underperform on specialized tasks without any mechanism to route to a better-suited alternative
LLM Routing Strategies Explained
There are two primary categories: static routing and dynamic routing. Static routing suits applications with well-defined, separated user workflows. Dynamic routing is required when all requests enter through a single interface.
Static Routing
Static routing directs requests to a specific provider or model based on a predetermined rule that doesn't change at runtime. The routing decision is typically driven by UI structure, API endpoint, or hard-coded model selection.
A practical example: a productivity tool with a separate interface component for content generation (routed to a creative model) and a different one for data summarization (routed to a cost-efficient model). The routing decision is made at design time, not request time.
Static routing is simple to implement and adds zero runtime overhead. It breaks down when request types are unpredictable or when all requests arrive through a single input.
Dynamic Routing
Dynamic routing intercepts each prompt in real time and decides programmatically which provider should handle it. This is required in virtual assistants, chatbots, and any system where all requests flow through a unified interface.
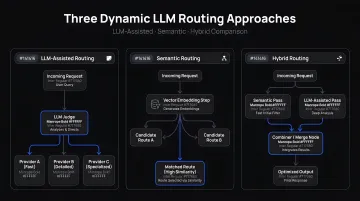
Three implementation approaches:
LLM-Assisted Routing A classifier LLM reads the incoming prompt and outputs a routing decision (for example, "technical support" vs. "billing inquiry"). This offers high accuracy for nuanced classification but adds latency and cost to every request. AWS measured LLM-assisted classification at 0.537–0.597 seconds versus roughly 0.1 seconds for semantic routing, at an estimated monthly cost of $188.90 vs. $107.90 at 100,000 daily questions.
Semantic Routing The system embeds the prompt as a vector and compares it against a reference index of labeled example prompts using similarity search. No additional LLM inference step is required, making it faster and cheaper. The trade-off: accuracy degrades if the reference set isn't kept current. This approach scales particularly well when there are many categories and new domains are added frequently.
Hybrid Routing For applications with both broad and fine-grained routing needs, semantic routing handles initial broad categorization (billing vs. technical) while a specialized classifier LLM makes the fine-grained decision within that category. This combines the scalability of semantic search with the precision of classifier models.
For teams that don't want to build or maintain this classifier infrastructure, FastRouter provides dynamic routing out of the box. Its auto model routes each prompt to the best-fit model from over 100 options, optimizing for quality, contextual relevance, and cost without custom pipeline work.
How Multi-Provider LLM Routing Works End-to-End
The Request Flow
From the application's perspective, there's only one endpoint. Everything else — provider selection, authentication, failover — happens inside the routing layer. Here's the full sequence:
- Request enters the unified API endpoint (for example,
https://go.fastrouter.ai/api/v1) - Routing layer evaluates the request against routing policy — static rule or dynamic classifier/semantic engine
- Provider is selected based on routing decision; correct credentials are injected automatically
- Request is forwarded to the selected provider
- Response is returned to the application and logged for observability
The application sends one request. The provider complexity never surfaces in your code.
Inputs to the Routing Decision
The routing engine evaluates multiple signals per request:
- Prompt length and complexity
- Task type (summarization, reasoning, code generation, classification)
- User tier or session context
- Provider availability and current latency
- Remaining budget or token quota
Credential Management
Once a provider is selected, the routing layer needs to authenticate to it — and each provider has its own API key. A routing layer centralizes that credential storage, either through the platform's own key management (with BYOK support for teams that prefer to use their own provider credentials) or via integration with secrets managers. Application code never handles provider-specific auth logic directly.
Failover Behavior
Failover in a routing system is policy-driven, not exception-driven. When a primary provider fails, the routing layer handles recovery automatically:
- Error response from provider → retry against fallback in the predefined chain
- Rate limit hit → route to next available provider
- Latency threshold exceeded → switch before the request times out
Teams configure fallback lists in advance. No developer needs to catch an exception — the routing layer fires the policy.
Observability Requirements
When requests can be served by any provider, unified tracing becomes essential — otherwise there's no way to know whether your routing policy is actually working. The routing layer should emit per-request metadata including:
- Which provider was selected
- Response latency
- Token count
- Per-request cost
- Error codes and retry events
FastRouter's unified dashboard surfaces all of this across providers in a single view, with real-time metrics and searchable activity logs — so you can confirm that cost routing is reducing spend, latency routing is hitting SLAs, and failover chains are catching errors before users see them.
Key Factors That Affect Multi-Provider LLM Routing in Production
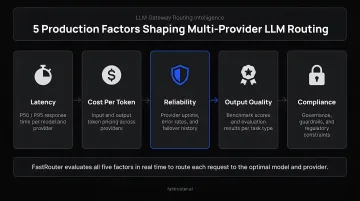
Five categories of inputs shape every production routing decision — understanding each one prevents the most common configuration mistakes.
Prompt characteristics — length, complexity, domain specificity, and task type directly determine which model tier is appropriate. A short classification prompt doesn't justify frontier model pricing; a multi-step reasoning task may fail on a lightweight model.
Model and provider attributes — each provider's strengths (reasoning capability, context window, fine-tuning depth), pricing structure, latency profile, and rate limits determine the routing policy. RouteLLM reports up to 85% cost reduction while maintaining 95% of GPT-5.5 performance on MT Bench, though results depend on accurate model capability data feeding the routing decisions. As a rough reference, Anthropic's Claude Haiku is priced at roughly $1/MTok input versus several multiples of that for Sonnet and Opus (verify current pricing before modeling) — routing even a fraction of simple tasks to the lighter model compounds meaningfully at scale.
Infrastructure dependencies — the routing layer must integrate with secret management, logging pipelines, and load balancers. In Kubernetes environments, the Gateway API enables Kubernetes-native backend definitions per provider.
Cost-quality trade-offs and throughput — high request volumes amplify every routing decision. Amazon Bedrock Intelligent Prompt Routing claims up to 30% cost reduction without compromising accuracy. RouterBench found LLM service costs varied 2x–5x for comparable performance across models, with an Oracle router achieving 0.957 performance at 0.297 cost versus GPT-5.5's 0.828 performance at 4.086 cost.
Safety, compliance, and data residency — GDPR Article 28 requires controllers to use only processors with sufficient guarantees; HIPAA requires a BAA before routing ePHI to any cloud provider. These constraints must function as hard routing rules that override cost or latency optimization — implement them as non-negotiable filters evaluated before any model selection logic runs.
Common Issues and Misconceptions in LLM Routing
Routing Is Not Load Balancing
Load balancing distributes traffic for availability and throughput. LLM routing selects the most appropriate model for each request based on content and context. Confusing the two leads teams to implement round-robin or availability-only routing that ignores quality and cost optimization entirely.
RouterBench confirms no single model optimally addresses all tasks when balancing performance and cost — so distributing requests evenly across models with different strengths produces inconsistent, often worse results than deliberate routing.
Where Teams Oversimplify
Common implementation mistakes:
- Treating routing as a one-time configuration rather than an evolving policy
- Building static routing for use cases that actually need dynamic classification
- Using a classifier LLM for routing without accounting for its latency and cost overhead on every request path
- Under-investing in the reference prompt set for semantic routing, leading to misclassifications as query patterns shift
These mistakes compound over time — and they often surface as something teams misdiagnose as a quality problem.
Routing vs. Output Quality
A routing system that correctly classifies every request is not automatically one that improves output quality. Routing directs traffic — quality still depends on model selection, prompt engineering, and fine-tuning. Teams sometimes blame poor output quality on routing failures when the underlying issue is that the routed model simply isn't the right model for the task. Evaluation infrastructure — A/B testing, side-by-side quality comparisons — is what validates whether routing decisions are actually hitting their target metric. The routing logic tells you where requests went; only evaluation tells you whether they ended up in the right place.
When Multi-Provider LLM Routing May Not Be the Right Fit
Multi-provider routing adds operational complexity that isn't always worth the tradeoff:
- Early-stage applications with low, homogeneous request volumes where a single provider handles all tasks well
- Applications where savings don't offset overhead: maintaining a routing layer, keeping policies current, and monitoring classifier accuracy can cost more than the routing saves
- Single-ecosystem SaaS products where managed routing features (such as Amazon Bedrock Intelligent Prompt Routing within the AWS ecosystem) already handle optimization without requiring a custom cross-provider layer
Signals That Routing Is Being Applied by Default, Not by Need
- The team can't articulate which criterion — cost, quality, latency, or compliance — is the primary routing driver
- Routing logic routes 90%+ of requests to the same provider regardless of task type
- No observability is in place to measure whether routing decisions are improving the target metric
- The classifier or semantic engine overhead approaches or exceeds the cost of using a single higher-quality model
If any of these apply, run the ROI math before building the routing layer — not after.
Frequently Asked Questions
What is the difference between an LLM router and an AI gateway?
An LLM router makes intelligent decisions about which model handles each request. An AI gateway provides the unified API surface, authentication, failover, and observability layer across providers. Most modern LLMOps platforms — including FastRouter — combine both functions into a single control plane alongside evaluations, guardrails, and cost governance; the distinction is primarily conceptual, not architectural.
What is the difference between static and dynamic LLM routing?
Static routing uses predetermined rules or UI-level separation to direct requests to specific models without real-time classification. Dynamic routing intercepts each prompt at runtime and selects a provider using a classifier model or semantic similarity engine. Static is simpler and adds no latency overhead; dynamic handles unpredictable mixed-intent traffic.
How does multi-provider LLM routing reduce inference costs?
Routing simple, high-volume tasks (classification, extraction, summarization) to lower-cost models avoids paying frontier-model pricing for requests that don't require it. Reserving premium models for complex reasoning keeps quality high where it matters. FastRouter's audit data shows an average achievable cost reduction of 46% across audited workloads.
What are the main challenges of implementing multi-provider LLM routing in production?
The core challenges include secure credential management across providers, keeping routing policies current as models evolve, classifier latency overhead, and building observability to confirm routing is hitting its target metric. Classifier accuracy matters: RouterBench found cascade performance degrades rapidly when judge error exceeds 0.2.
How does semantic routing differ from LLM-assisted routing?
Semantic routing uses vector embeddings and similarity search to classify requests without an extra LLM inference step — faster and cheaper, but dependent on a well-maintained reference prompt set. LLM-assisted routing handles ambiguous prompts with more nuance, at the cost of added latency and spend on every request.
Can I use multi-provider LLM routing without building a custom router from scratch?
Yes. Managed options include Amazon Bedrock Intelligent Prompt Routing for AWS-native workloads and open-source proxies like LiteLLM for self-hosted setups. FastRouter provides intelligent routing, a unified OpenAI-compatible API, automatic failover, and observability across 150+ models by simply replacing your API base URL — no custom engineering required.