Introduction
Gartner predicts 30% of generative AI projects will be abandoned after proof of concept by end of 2025 — not because the technology failed, but because costs outpaced the business case.
The pattern is consistent: a pilot runs cleanly on a small dataset with a defined team. Then usage spreads. More teams, more use cases, more tokens. Token fees compound. Idle GPU infrastructure bills continuously. Data storage expands. What was a $15,000 quarterly experiment becomes a finance escalation.
The underlying problem is rarely the model itself. GenAI costs get out of hand because of specific decisions made (or skipped) at the planning, deployment, and operational stages. Model selection, governance design, infrastructure choices, and rollout strategy all create cost exposure that compounds until scale makes it visible.
Cost optimization for generative AI is a core function within LLMOps — the operational discipline of running LLMs reliably in production. This guide covers cost reduction across three dimensions: upfront decisions, operational controls, and the surrounding setup factors — data quality, compliance infrastructure, rollout strategy — that are often the real cost driver.
For teams operationalizing this, FastRouter is the LLMOps platform — one OpenAI-compatible API across 150+ models, sub-10ms overhead, zero markup, with built-in observability and cost governance.
Key Takeaways
- Small GenAI pilots quietly balloon as token volume, idle compute, and data infrastructure costs stack up
- Top cost drivers: inference at scale, data prep, compliance overhead, maintenance, and untracked shadow AI spend
- Most teams waste 40%+ of their AI budget routing routine tasks to expensive frontier models that are overkill
- Spending you can't see is spending you can't control — visibility is the most underrated cost lever
- AI cost optimization is an ongoing discipline, not a one-time budget trim
How Generative AI Costs Typically Build Up
GenAI costs rarely arrive as a single large invoice. They accumulate gradually, and the full picture only becomes clear once production load hits.
The build-up follows a predictable pattern:
- Token fees scale directly with usage volume — each team added multiplies consumption
- Provisioned infrastructure bills continuously, including during idle periods between workloads
- Data storage expands as training datasets, retrieval indexes, and logs grow
- Maintenance demand increases proportionally with system complexity
Several costs stay hidden until production load or regulatory scrutiny arrives. Cloud egress fees, compliance overhead, technical debt from AI-generated code, and model drift remediation rarely surface during pilots. Research from MIT Sloan Review highlights that AI-generated code specifically carries hidden maintenance costs that teams consistently underestimate.
Once these costs surface, the position is already difficult. Infrastructure is provisioned and hard to walk back, teams have built workflows around specific tooling, and retrofitting governance adds overhead without recovering what was already spent. Getting ahead of these dynamics — before production commits the spend — is what effective cost optimization actually looks like.
Key Cost Drivers for Generative AI
Compute and Inference
Compute is the most visible driver. GPU costs during training and API token fees during inference scale rapidly with usage volume. Standard per-token pricing from major providers illustrates the exposure at scale:
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| GPT-5.5 Search Preview | $2.50 | $10.00 |
| Gemini 3.1 Pro | $1.25 | $10.00 |
| Claude Sonnet 4 | $3.00 | $15.00 |
| xAI Grok 4.3 | $3.00 | $15.00 |
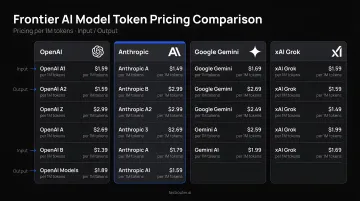
At high volume, the difference between routing every request to a frontier model versus a cost-appropriate alternative is substantial. Internal audit data from FastRouter shows teams achieve an average 46% cost reduction simply by stopping the default to expensive models for tasks that don't require them.
Data Infrastructure
Data costs compound in ways that rarely appear in initial budget estimates. Storage for large training datasets, vector databases for RAG pipelines, and the labor-intensive process of cleaning and structuring enterprise data can collectively rival model costs — particularly in regulated industries like healthcare, finance, or legal services.
Ongoing Talent and Maintenance
ML engineers, prompt engineers, and monitoring specialists don't free up after deployment. They enter a continuous cycle of evaluation, iteration, and integration updates. Gartner's AI Debt framework documents that ongoing maintenance typically consumes a significant share of the original AI build investment — a cost most project budgets ignore entirely.
Governance and Compliance
Compliance infrastructure adds persistent operational overhead that teams rarely budget for upfront. Required components typically include:
- Audit trails and access logging
- PII detection and data masking
- GDPR documentation (fines reach €20 million, roughly $22 million, or 4% of global annual turnover)
- HIPAA-compliant logging (civil penalties extend into the millions per violation category)
These costs materialize in production — not during planning — which is precisely when they're hardest to absorb.
Cost-Reduction Strategies for Generative AI
No single strategy reduces GenAI costs universally. The right approach depends on where cost is originating: a poor upfront decision, an operational gap, or a structural or environmental gap.
Strategies That Change Upfront Decisions
The most expensive GenAI mistakes are made before a system goes live. These strategies target decisions made at or before deployment — where a single wrong call compounds into months of excess spend.
Right-size model selection to task requirements. Defaulting to frontier models for every request is the most common and expensive early mistake. Map task complexity to model capability:
- Complex reasoning, multi-step agentic workflows → frontier models justified
- Classification, summarization, FAQ responses → smaller, cheaper models perform equivalently
- High-volume, low-stakes queries → cost-optimized routing saves the most here
FastRouter's Auto Router (fastrouter/auto) automates this by routing each prompt to the best-fit model across 100+ options, optimizing for quality, cost, and contextual relevance without requiring manual configuration per task.
Evaluate build vs. buy vs. fine-tune deliberately. Organizations overbuild by training custom models when fine-tuning a pre-trained model — or simply using a managed API — delivers comparable results at a fraction of the cost.
Fine-tuning via LoRA or QLoRA requires substantially less compute than training from scratch. For most enterprise use cases, a well-configured managed API outperforms a custom model that took months to build.
FastRouter's Model Council and Playground lets teams compare latency, output quality, and cost across models in side-by-side evaluations — generating evidence for the build vs. buy decision before architecture commitments are made.
Define explicit use case scope before deployment. Undefined scope causes feature creep that drives unnecessary infrastructure provisioning and model complexity. A tightly scoped use case with measurable success criteria constrains spending and makes ROI demonstrable.
Strategies That Change How GenAI Is Managed
Once systems are running, cost leakage typically comes from poor visibility and absent guardrails. These strategies close the gap between what is provisioned and what is actually used.
Implement LLM traffic routing by task complexity. Routing all prompts through a single expensive model ignores significant cost opportunity. Research on LLM routing frameworks shows cost reductions of up to 66% while maintaining near-equivalent performance — by directing simple, high-volume queries to cheaper models and reserving frontier capacity for reasoning-intensive tasks.

Enforce team-level budget caps with real-time alerting. Consumption-based pricing with no guardrails is a primary cause of end-of-quarter finance escalations. FastRouter supports project and API key-level budget limits with real-time alerts that trigger the moment spend, latency, or error rates breach defined thresholds — converting cost management from reactive to proactive.
Centralize cost visibility across all models and providers. Fragmented tooling — separate dashboards for different models, cloud accounts, and teams — creates financial blind spots. FastRouter's consolidated billing aggregates invoices and spend across OpenAI, Anthropic, Gemini, and other providers into one reconciled view with per-team spend attribution.
Audit and eliminate shadow AI spend. When centralized procurement moves slowly, teams independently adopt AI tools — creating overlapping functionality, duplicated subscriptions, and unvetted data exposure. Cisco's 2024 Data Privacy Benchmark Study found that organizations using AI tools outside IT oversight face compounded security and cost exposure.
A unified API gateway like FastRouter addresses this structurally by channeling all AI access through a single controlled endpoint — preventing future fragmentation rather than just auditing past spend.
Strategies That Change the Context Around GenAI
Sometimes the model isn't the problem. These strategies tackle the environment around the system — where the setup drives costs the model can't fix on its own.
Invest in data quality before model deployment. Poor-quality training or retrieval data drives hallucinations, failed evaluations, and repeated retraining cycles — each consuming GPU resources and engineer time. Front-loading data cleaning and validation reduces the total cost of reaching a reliable, production-ready system.
Design compliance and governance infrastructure before deployment, not after. Retrofitting audit trails, PII detection, and regulatory documentation into an already-deployed system is significantly more expensive than building them in. FastRouter's enterprise governance controls — including PII masking, data-residency controls, compliance logging, and audit trails — can be configured before any traffic reaches production.
Use spot instances, reserved capacity, and tiered storage. Organizations paying on-demand rates for predictable workloads leave meaningful savings unrealized:
- Reserved instances for baseline load → predictable savings vs. on-demand
- Spot instances for fault-tolerant batch workloads → AWS EC2 spot pricing offers up to 90% discount vs. on-demand
- Tiered storage (moving infrequently accessed data to lower-cost tiers) → reduces storage costs without affecting model performance
Adopt a phased rollout to validate ROI before scaling spend. Deploying broadly before validating performance and usage patterns locks in infrastructure costs for use cases that may not deliver value. FastRouter's Experiment Tracking and Evaluations features support structured pilots — A/B testing models, comparing quality and cost, and generating evidence for scale decisions based on actual demand rather than projected adoption.

Conclusion
Sustainable AI cost management starts with knowing where cost actually originates — a poor upfront model choice, an operational gap, or a misconfigured workflow — and addressing that specifically, rather than applying broad budget cuts that reduce capability without solving the underlying problem.
The organizations that scale AI sustainably maintain continuous visibility into what's being spent, on what, and why. Cost drivers shift as AI initiatives mature: what's expensive at the pilot stage differs from what's expensive at enterprise scale. A quarterly audit that catches token bloat in one quarter may miss provider pricing changes in the next. Optimization works when it's built into how teams operate — not treated as a one-time cleanup before the next budget review. FastRouter's LLMOps platform helps engineering teams maintain that discipline by surfacing spend, routing decisions, and quality signals in one place — alongside evaluations, guardrails, and governance — without requiring manual tracking across providers.
Frequently Asked Questions
How can businesses use generative AI to reduce costs?
Businesses cut GenAI operational costs through better model selection, usage governance, and visibility tools. GenAI also reduces business costs by automating workflows in content creation, customer support, and data analysis — labor savings that offset infrastructure spend when measured correctly.
What is cost optimization for AI?
AI cost optimization is the systematic process of identifying, monitoring, and reducing expenses associated with deploying and running AI systems. It covers compute, data infrastructure, talent, compliance, and vendor spend across the full AI lifecycle — not just the model bill.
Why is training AI expensive?
Large model training demands weeks or months of continuous GPU computation across massive datasets — costs scale with model size, data volume, and run duration. For most business use cases, fine-tuning a pre-trained model via LoRA is far more cost-effective than training from scratch.
What is the cheapest way to deploy generative AI for business use?
Managed APIs suit low-to-moderate volume best; self-hosting an open-source model on cloud infrastructure cuts per-query costs for high-volume internal workloads. In either case, task-based routing — using simpler models where frontier performance isn't needed — delivers the largest marginal savings.
What is shadow AI spend and how does it affect my AI budget?
Shadow AI spend refers to unsanctioned AI tool purchases and API integrations made by individual teams outside central IT oversight. It creates duplicated costs, security exposure, and budget blind spots that inflate the true cost of AI across the organization without appearing in any centralized budget view.
How do you measure ROI on generative AI investments?
GenAI ROI should compare total deployment and maintenance costs against quantifiable business outcomes — time saved, error rates reduced, revenue enabled. ROI tracking should begin at the pilot stage using defined success metrics, before costs are allowed to scale to production levels.