Introduction
Building an impressive LLM demo takes a weekend. Getting it to production — and keeping it there — is an entirely different challenge.
Teams discover this the hard way. Gartner predicted that 30% of GenAI projects would be abandoned after proof of concept by end-2025, citing escalating costs, poor data quality, and inadequate risk controls. S&P Global found organizations scrap 46% of PoC projects before production on average. The prototype gap is real.
The teams that close that gap share a common foundation: operational discipline around LLMs, or LLMOps.
This guide breaks down what LLMOps is, how it differs from traditional MLOps, its core components, who needs it, and what separates teams that ship reliable AI from those stuck in pilot purgatory.
Key Takeaways
- LLMOps is the operational layer that bridges a working LLM prototype and a stable, scalable production application
- Unlike MLOps, LLMOps is inference-first — centered on prompt behavior, output quality, and runtime cost control
- Core components include prompt management, model routing, observability, cost governance, and security guardrails
- Any team running LLMs in production faces LLMOps challenges, not just AI-native companies
- Version everything, embed evaluation into your deployment pipeline, and treat monitoring as ongoing — not a one-time launch check
What Is LLMOps?
LLMOps (Large Language Model Operations) is the set of practices, tools, and workflows for deploying, monitoring, maintaining, and optimizing large language models in real-world production environments. It's the operational layer that bridges a working prototype and a stable, scalable application.
Why LLMOps Is Different from Traditional Software Operations
LLMs aren't just another API call. Three properties make them operationally unique:
- Non-determinism: The same prompt can produce different outputs across runs — traditional software assertions won't catch this.
- Token usage adds up fast, especially in multi-step agent workflows, and costs can spike without warning.
- Output quality can't be measured with unit tests. It requires qualitative judgment, not pass/fail logic.
These properties shift the operational challenge from keeping a service alive to actively managing language, cost, and behavior — at scale, in production.
What LLMOps Actually Covers
LLMOps is not just calling an LLM API or picking the right model. Because language models touch cost, quality, and compliance simultaneously, a complete setup needs to address all three layers at once. That typically means:
- Prompt versioning and template management
- Multi-provider model routing with fallback logic
- Real-time observability and inference tracing
- Token cost tracking and budget governance
- Output quality evaluation and LLM-as-a-judge scoring
- Security guardrails, PII filtering, and compliance audit logs

Why LLMOps Matters: The Challenges It Solves
Non-Deterministic Outputs
Researchers testing five LLMs across eight tasks found that nondeterminism remains a persistent methodological challenge even under deterministic settings. You can run the same prompt twice and get meaningfully different responses — different tone, different facts, sometimes contradictory conclusions.
Traditional software testing assumes reproducibility. LLMOps addresses this gap through structured evaluation frameworks and LLM-as-a-judge scoring. Research from MT-Bench and Chatbot Arena shows this approach aligns strongly with human preferences when GPT-4 acts as the judge.
Prompt Fragility and Drift
Small prompt changes — formatting tweaks, word order adjustments, few-shot example selection — can dramatically alter output quality. An OpenReview paper on prompt sensitivity found that widely used open-source LLMs are extremely sensitive to subtle formatting changes in few-shot settings.
Without prompt version control, teams have no way to trace what changed, when it changed, or why their product degraded last Tuesday.
Cost Escalation
Enterprise GenAI spend hit $37 billion in 2025, up from $11.5 billion in 2024 — a 3.2x year-over-year increase. Multi-step agent workflows are particularly dangerous: each tool call or reasoning step adds tokens, and costs compound quickly. Without active monitoring and governance, LLM spend becomes unpredictable at scale.
Gartner specifically cited escalating costs as a primary reason GenAI projects get abandoned after PoC. Teams that skip cost governance at the PoC stage typically face hard budget ceilings before they reach production.
Security and Compliance Gaps
OWASP's 2025 Top 10 risks for LLM applications lists Prompt Injection and Sensitive Information Disclosure at the top. Stanford HAI reported 233 AI incidents in 2024, up 56.4% year over year.
Prompt injection attacks, PII leakage through model outputs, and uncontrolled generation in regulated environments aren't edge cases. Each requires dedicated guardrails built into the deployment pipeline — input filtering, output scanning, and audit logging at minimum.
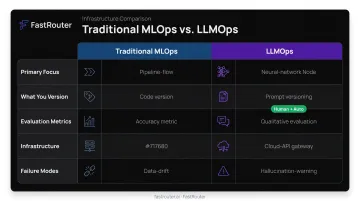
LLMOps vs. MLOps: Key Differences
LLMOps builds on MLOps principles but addresses a different operational reality:
| Dimension | Traditional MLOps | LLMOps |
|---|---|---|
| Primary focus | Training pipelines, feature engineering | Inference, prompt behavior, runtime control |
| What you version | Model weights, datasets | Prompt templates, model configs |
| Evaluation metrics | Precision, recall, F1 | Hallucination rate, groundedness, tone, toxicity |
| Infrastructure | Batch, deterministic, data-driven | Real-time, multi-provider, token-level cost tracking |
| Failure modes | Model drift, data pipeline errors | Prompt regression, cost spikes, output safety issues |
The Shift from Model Versioning to Prompt Versioning
In LLMOps, the "code" is often the prompt template — most teams using a hosted model like GPT-4 or Claude control behavior entirely through prompts, never touching the model weights directly. This shifts operational focus toward tracking prompt iterations, A/B testing variants, and rolling back to previous versions when quality drops.
Why LLM Evaluation Requires Qualitative Judgment
Traditional ML models are evaluated against labeled datasets with objective metrics. LLMs require qualitative judgment. G-Eval research showed that conventional metrics like BLEU and ROUGE have limited alignment with human judgment — GPT-4-based evaluation outperforms them. In practice, this means LLMOps teams need scoring frameworks that can assess tone, factual groundedness, and safety — not just numeric accuracy.
Core Components of LLMOps
LLMOps is an operational stack, not a single tool. Each component addresses a specific failure mode teams encounter when running LLMs in production.
Prompt Management
Prompts are the primary lever for controlling LLM behavior. Prompt management involves creating, versioning, testing, and deploying prompt templates so changes are tracked, experiments are reproducible, and regressions can be rolled back.
Think of it as Git for your model's behavior: a clear audit trail that makes debugging a quality drop a matter of checking the history rather than guessing what changed.
Model Routing and Multi-Provider Orchestration
Production systems rarely rely on a single model. Model routing enables dynamic traffic distribution across providers — OpenAI, Anthropic, Google Gemini, Mistral, open-source models — with:
- Fallback logic when a provider goes down
- Load balancing across providers at rate limits
- Latency-based routing for real-time applications
- Cost-based routing to cheaper models for simple tasks
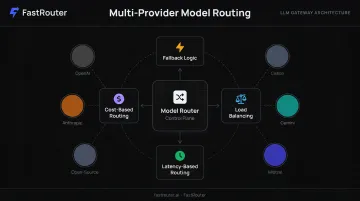
Platforms like FastRouter provide an OpenAI-compatible control plane that unifies routing across 100+ models without requiring application-level code changes. Teams can define fallback model lists and virtual model aliases that transparently resolve to multiple providers — so a single API call can survive provider outages automatically.
Monitoring and Observability
Production LLM observability covers more than uptime metrics:
- Tracing individual inference calls end-to-end
- Logging prompt-response pairs for quality review
- Tracking latency, token usage, and error rates per model and provider
- Running continuous quality checks to catch degradation before users notice
According to a McKinsey survey on generative AI adoption, less than 20% of organizations track well-defined KPIs for their GenAI solutions. Observability is where most teams are still underinvested.
Cost Governance
Token usage from multi-step agents or high-traffic endpoints can generate unexpected bills fast. Cost governance includes:
- Per-project and per-API-key budget quotas
- Real-time spend alerts for usage anomalies
- Model selection policies that route to cheaper models when quality requirements allow
- Unified dashboards showing spend by provider, model, and project
Based on FastRouter's internal audit data, organizations using smarter model selection and routing policies have seen an average cost reduction of 46%, translating to roughly $1,240 in monthly savings per organization.
Security, Guardrails, and Compliance
LLMs introduce a distinct category of security risks that traditional software stacks weren't built to handle:
- Input/output filtering for PII detection and harmful content
- Prompt injection defenses to prevent user inputs from hijacking model behavior
- Role-based access control over model endpoints and API keys
- Audit logs required for regulated industries like healthcare and finance
Who Needs LLMOps and Key Use Cases
Any team running LLMs in production faces LLMOps challenges. The most common adopter profiles:
- Engineering teams shipping AI-powered products who need reliability and cost control
- Data science teams managing multiple models across different use cases
- Enterprise IT teams accountable for governance, compliance, and spend
Key Use Cases
| Use Case | Core LLMOps Requirements |
|---|---|
| Enterprise knowledge bots (RAG) | Retrieval quality evals, access controls, answer monitoring |
| Customer support automation | Cost monitoring, escalation rules, hallucination tracking |
| Code assistants | Security review, usage telemetry, code-quality evals |
| Content generation pipelines | Brand/style evals, factuality checks, human approval workflows |
| Clinical note summarization | PHI handling, auditability, clinician review, compliance monitoring |
| Legal contract review | Traceability, output accuracy evals, audit trails |
Scale makes every gap visible. The Klarna AI assistant handled 2.3 million conversations in its first month — two-thirds of all customer service chats. At that volume, even a 1% hallucination rate becomes a serious operational problem. Cost monitoring and error tracking aren't optional features; they're what makes the deployment sustainable.
Industries Where LLMOps Governance Is Non-Negotiable
- Financial services: Regulators expect documented audit trails, spend controls, and explainable outputs — not just accurate ones
- Healthcare: HIPAA-covered data requires strict PHI handling, output safety checks, and clinician-in-the-loop review before any response reaches a patient
- Legal tech: Every AI-assisted document analysis needs full input-output traceability to hold up under scrutiny
- Education: Deployed at scale across age groups, LLMs need continuous bias monitoring and content filtering to stay appropriate
LLMOps Best Practices
Version Everything
Prompt templates, model configurations, and evaluation datasets should all be version-controlled — just like application code. This enables teams to reproduce results, debug regressions, and roll back safely.
At minimum, track:
- Prompt templates and their change history
- Model configurations (provider, version, parameters)
- Evaluation datasets and scoring criteria
If you can't answer "what prompt was running last Thursday at 3pm," you don't have enough version control.
Build Evaluation into the Deployment Pipeline
Running automated evaluations before any prompt or model change reaches production transforms LLM quality from a manual spot-check into a CI/CD gate. This means:
- Define evaluation criteria upfront — hallucination rate, tone, groundedness, task completion
- Build a scored test set of representative inputs and expected outputs
- Run evals automatically on every prompt or model configuration change
- Block deployment if quality scores drop below threshold

FastRouter handles this as part of its core workflow — experiment tracking and evaluations run alongside routing and observability in a single platform, so teams don't have to wire together separate tools to cover each piece.
Monitor Continuously, Not Just at Launch
LLM behavior shifts over time — due to model updates from providers, prompt changes by your own team, or distribution shifts in user inputs. McKinsey found that 58% of organizations actively manage risks related to inaccuracy, but review coverage varies widely: about 30% check 20% or less of GenAI content before use.
Teams that catch problems early are monitoring quality scores, latency, cost metrics, and error rates continuously — not waiting for users to report something broken.
Frequently Asked Questions
What is the purpose of LLMOps?
LLMOps exists to bring operational discipline to large language models in production. It ensures LLMs perform reliably, behave safely, scale cost-efficiently, and can be monitored and improved continuously — without constant manual intervention from your engineering team.
What is the difference between MLOps and LLMOps?
MLOps focuses on training pipelines, feature engineering, and accuracy metrics for traditional ML models. LLMOps is inference-first and addresses the unique challenges of prompt management, non-deterministic outputs, token cost governance, and behavioral monitoring that emerge specifically when running large language models in production.
What tools are used in LLMOps?
The main categories include: model routing and AI gateways, prompt management systems, observability and tracing platforms, evaluation frameworks, and cost governance dashboards. Examples range from MLflow and Weights & Biases for experiment tracking to unified platforms like FastRouter that consolidate routing, observability, evaluations, and cost governance into a single control plane.
What are the stages of LLMOps?
The typical lifecycle covers: data preparation and prompt engineering, model selection or fine-tuning, deployment and routing setup, monitoring and evaluation, and continuous iteration based on production feedback. Unlike traditional ML, the cycle is faster and more iterative — prompt changes can ship in hours, not weeks.
What is an LLMOps platform?
An LLMOps platform consolidates the tools needed to deploy, govern, monitor, and optimize LLMs into a single operational control plane — replacing a fragmented stack of standalone gateways, logging tools, eval frameworks, and cost dashboards. Accessible to both engineering and product teams.
What is the future of LLMOps?
LLMOps is moving toward automation, multi-model orchestration, and agentic workflows — what some call AgentOps. Gartner predicts 40% of enterprise apps will feature task-specific AI agents by 2026. That shift means LLMOps controls will need to cover multi-step tool calls, per-agent cost limits, and trace-level debugging of autonomous runs.


