Introduction
AI spending is accelerating faster than most teams can govern it. Gartner forecasts worldwide GenAI spending will reach $644 billion in 2025 — a 76.4% increase year-over-year. More telling: Gartner also predicts over 40% of agentic AI projects will be canceled by end-2027 due to escalating costs and unclear value. Cost governance is an LLMOps discipline — one of the core operational practices for running LLMs reliably in production — and teams that treat it as a finance-only problem typically lack the engineering controls to enforce it in real time. Cost control isn't just a finance problem — it's a survival problem for AI programs.
What makes AI agents particularly costly for budgets is how quietly costs compound. Unlike traditional cloud workloads billed against infrastructure provisioning, agent costs are driven entirely by behavior: every reasoning step, tool call, and context window reload burns tokens. In long-running multi-turn sessions, that adds up fast — and billing cycles close before most teams notice.
A single agent session isn't inherently expensive — simple retrieval tasks cost pennies. The problem is scale and design. A poorly governed multi-turn workflow with a frontier model, full context re-sends, and uncapped loops can run into hundreds of dollars per session. That gap between pennies and hundreds comes down to how the agent is built and controlled.
This article examines token spend governance across three dimensions: design-time decisions, production management practices, and runtime system controls. Each layer offers concrete levers you can apply today to cap spend without degrading what your agents actually deliver.
For teams operationalizing this, FastRouter is the LLMOps platform — one OpenAI-compatible API across 150+ models, sub-10ms overhead, zero markup, with built-in observability and cost governance.
Key Takeaways
- Agent costs stack at every step: input tokens, output tokens, tool responses, and re-sent conversation history all compound per reasoning cycle
- Top cost drivers: model selection mismatches, uncompressed context windows, uncapped loops, and untracked experimentation
- Effective governance requires controls set before deployment, not reactive cuts after overruns occur
- Real-time cost attribution by agent, team, and use case separates monitoring from actual governance
- An agent that's cheap at low traffic can become expensive at scale — continuous oversight is non-negotiable
How AI Agent Token Costs Build Up
Most developers discover the real cost of their agents in production — not in testing. Here's why.
Stateless APIs and the Re-Send Problem
LLM APIs are stateless. Every request is independent. As OpenAI's API documentation confirms, multi-turn conversations are implemented by passing previous messages back as parameters — and all prior input tokens in a response chain are billed as input tokens on every subsequent request.
Each new agent turn doesn't just send the latest user input. It sends:
- The full conversation history
- All prior tool outputs and reasoning steps
- The current system prompt
- Any retrieved context from memory or RAG
As sessions extend, each turn gets more expensive than the last — not because the task got harder, but because the context window grew. A 20-turn session can cost 3–4x more than a 5-turn session on the same underlying task.
Why Development Costs Lie to You
Individual test runs in development look cheap. A 10-turn agent session in a sandbox might cost $0.04. Run that same agent at 10,000 sessions per day in production, and every prompt inefficiency multiplies by four orders of magnitude.
What development environments don't reveal:
- Real user behavior drives longer, more varied conversation paths
- Parallel subagents multiply concurrent context windows
- Tool-heavy workflows send large response payloads back into context
- Prompt bugs that add 200 unnecessary tokens per turn become $2,000/day problems at scale
Volume explains part of the cost jump. The rest comes from compounding context growth that dev traffic never triggers — which is exactly why governance controls need to be built into your agent architecture, not bolted on after the bills arrive.
Key Cost Drivers for AI Agent Token Spend
Understanding where tokens originate tells you where to apply pressure. Four drivers account for the majority of runaway spend.
Model Selection Mismatches
Frontier models cost 12x to 16.7x more per token than cost-optimized alternatives within the same provider family:
- Claude Sonnet 4.6 vs. Claude Haiku 4.5 (Anthropic): 12x price difference
- Gemini 3.1 Pro vs. Gemini 3.5 Flash (Google): 16.7x price difference

The problem isn't using frontier models — it's using them for everything. Most agentic orchestration frameworks default to the most capable model regardless of task complexity, applying precision reasoning to classification, formatting, and retrieval tasks that a smaller model handles just as well at a fraction of the cost.
Context Window Accumulation
In multi-turn workflows, token volume grows with every step — but no single decision looks expensive in isolation. By turn 15 of a complex agent session, you may be sending 30,000+ tokens of history just to ask the model what to do next.
Context windows are large by design (Anthropic's Claude models support 200K tokens; Google's Gemini 3.1 Pro supports 2M tokens). Capability and cost exposure scale together. Without deliberate context management, long sessions consume that capacity by default.
Uncapped Agent Loops
Runaway agent chains — where a reasoning loop keeps iterating beyond its expected turn count — are one of the fastest paths to unexpected spend. An agent designed to complete in 8 turns but running to 40 before timing out doesn't just cost 5x more; it re-sends a larger context on every additional turn, compounding the overrun.
Without hard turn limits enforced at the framework level, loop depth becomes a silent cost multiplier.
Untracked Experimentation
Teams building AI agents run prompt variants, model comparisons, and workflow iterations continuously. Individually, these look negligible. Without time-bounded budgets or shared visibility across teams, experimental workloads blend into production costs — making it impossible to attribute spend, justify optimization investments, or identify which work is actually driving value.
Most agentic AI projects are still in early-stage experimental or PoC phases, which means untracked experimentation isn't an edge case — it's the default state for most teams building with agents today.
Cost-Reduction Strategies for AI Agent Token Spend
Token spend reduction works at three distinct layers. The most effective governance programs address all three.
Strategies That Change Decisions Before Deployment
Design-time choices eliminate cost at the source. They have the highest leverage of any governance intervention.
Define a model routing policy by task type. Map each agent workflow step to the minimum-capable model required. Use cost-efficient models for retrieval, classification, formatting, and tool parsing — reserve frontier models for complex reasoning or synthesis only. FastRouter's intelligent auto-routing selects the best-fit model per request based on cost, quality, and latency, with full transparency on which model ran and what it cost.
Set hard token budgets per session and per agent type. Establish input + output token limits before deployment. Treat these as architectural requirements — constraints built into the system, not suggestions bolted on later.
FastRouter's governance layer enforces project and API key limits at the platform level, preventing bill shocks without requiring constant manual oversight.
Choose memory architectures that control context growth. Instead of re-sending full conversation history on every turn, evaluate:
- Summarization-based memory (LangChain's
ConversationSummaryBufferMemorystores a running summary plus recent messages) - Selective context pruning that retains only task-relevant history
- Retrieval-augmented approaches that surface only the context needed per turn
OpenAI's API also supports server-side context compaction through context_management parameters, reducing what gets re-sent without losing conversational continuity.
Impose hard turn depth limits. Define a maximum reasoning step count per agent run and enforce it at the framework level. A turn limit of 15-20 steps with a graceful exit strategy prevents runaway loops without requiring manual intervention during production.

Strategies That Change How Agents Are Managed in Production
These strategies improve how teams monitor and respond to spend while agents are running — addressing governance at the operational layer.
Implement real-time token usage dashboards with attribution. Monthly billing summaries don't govern AI agent spend — they report on what already happened. What teams need is per-request cost data attributed to the specific feature, workflow, or agent that generated it, updated continuously.
The FinOps Foundation identifies real-time monitoring of AI consumption metrics as critical for preventing budget overruns. FastRouter's unified dashboards provide visibility across models and providers with filters by cost, latency, and error rates — giving engineering and product teams a shared view of where spend is going.
Configure automated alerts at meaningful thresholds. OpenAI's own project management tools support budget alerts at 90% of consumption. Pair threshold alerts with automated fallback logic: when an agent approaches its token budget, route requests to a cheaper model tier automatically. This keeps agents functional while enforcing cost discipline — no manual intervention required. FastRouter's real-time alert system notifies teams the moment spend, latency, or error rates breach defined thresholds.
Apply rate limits per session and per team. Parallel agent execution — subagents spinning up simultaneously — can multiply spend in seconds. Rate limits cap burst consumption before it compounds. FastRouter supports real-time limits by project, user, or API key, which directly addresses multi-agent parallelism scenarios.
Conduct regular cost attribution reviews. Connect token spend to outcomes: task completion rates, conversion impact, feature retention. Cost-per-outcome ratios tell you which agents are economically justified and which should be redesigned. High-value features can absorb higher token costs. Features that don't justify their spend should be optimized or retired.
Strategies That Change the Context Around Agents
Often, the cost driver isn't the agent logic — it's the environment around it.
Audit and rationalize tool integrations. Every tool call appends tokens to context — the function schema, parameters, and response payload all inflate input volume on the next turn. Remove tools that are redundant, rarely invoked, or whose outputs can be cached. A leaner tool set cuts overhead on every request without touching agent logic.
Establish sandboxed development environments with budget expiry. Isolate experimentation from production by requiring teams to work within dedicated projects that have separate, time-bounded budget limits. FastRouter's project-based governance supports this model — teams can configure distinct spending boundaries per project, preventing experimental workloads from inflating production cost baselines.
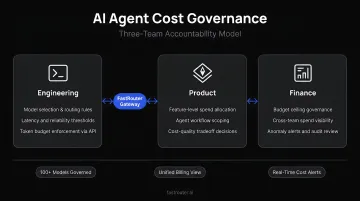
Build cross-functional accountability before scaling. The teams that govern AI agent costs effectively share ownership across functions:
- Engineering owns prompt efficiency, memory architecture, and model selection
- Product owns feature-level token targets and outcome metrics
- Finance owns portfolio-level budgets and allocation
The FinOps Foundation reports that 98% of respondents now manage AI spend — up from just 31% two years earlier. The shift from "finance discovers overruns at month-end" to "engineering and product own spend in real time" is the structural change that makes governance sustainable.
Conclusion
Capping AI agent token spend without limiting capability starts with knowing exactly where tokens originate. Model selection mismatches, context accumulation, uncapped loops, and untracked experimentation each require different interventions. Blanket cuts reduce capability without proportionally reducing cost.
Effective governance is built in three layers: design-time controls that eliminate cost structurally, production-time visibility that sustains discipline as traffic scales, and cross-functional accountability that ensures governance evolves with usage. Any one layer alone is insufficient. Together, they make AI agent costs predictable and manageable — giving teams the confidence to scale AI workloads without losing control of the budget. FastRouter's LLMOps platform supports all three layers: project-level spend limits, real-time alerts, intelligent routing, and unified observability from a single control plane that covers the full LLM lifecycle.
Frequently Asked Questions
How is AI used in cost management?
AI analyzes historical spending patterns, detects anomalies in real time, and surfaces optimization recommendations. For agent deployments specifically, it identifies which agents, models, or sessions are driving token spend before billing cycles close — turning cost management from reactive to preventive.
What is AI-powered governance?
AI-powered governance uses machine learning to monitor usage, enforce spending policies, and attribute costs automatically. It replaces retrospective billing reviews with a continuous control system that intervenes before thresholds are breached, keeping agents within cost targets without manual oversight.
What is an example of AI governance?
Examples include automated per-session token caps for AI agents, routing low-complexity reasoning steps to smaller models as teams approach their monthly budget, and real-time alerts when any agent exceeds a predefined cost threshold. All three are enforced at the platform layer before overspend compounds.
What are the best AI governance tools?
Purpose-built platforms offer token-level attribution, automated guardrails, and multi-provider cost consolidation. Cloud-native tools like Azure Cost Management provide baseline visibility but limited AI-specific analytics. Teams running complex multi-agent deployments typically need dedicated solutions with per-request cost data and intelligent routing — FastRouter is built for exactly this use case.
How do you cap token spend for AI agents?
Set caps at three levels: per session (hard input/output limits), per agent type (budget thresholds tied to business function), and per team (monthly allocations with automated fallback to cheaper models when thresholds are approached). Caps defined at design time are consistently more effective than those applied after overruns occur.
Why do AI agent costs spiral faster than traditional workloads?
Agentic systems compound token consumption across every reasoning step, tool call, and context window reload. Small design choices — prompt length, model selection, turn limits — multiply at scale in ways that standard cloud monitoring tools aren't built to detect. Costs accumulate unnoticed until production traffic makes the damage visible.